強化学習の世界を俯瞰してみる - 基礎から最前線の課題・応用・トレンドまで

強化学習(RL)は、エージェントが試行錯誤を通じて最適な行動を学習する機械学習の一分野です。近年、囲碁やビデオゲーム、大規模言語モデル(LLM)の制御など、多岐にわたる分野で著しい進展を遂げ、応用されています。
特に、深層学習と組み合わせた深層強化学習(DRL)は、高次元の状態空間や行動空間を扱う能力により、AI技術の可能性を大きく広げました。しかし、DRLポリシーの汎化能力の限界や、実世界への展開における安定性、説明可能性といった課題も依然として存在します。
今回は、強化学習の基本概念から主要アルゴリズム、、そしてPyTorchベースの強化学習ライブラリであるStable Baselines3(SB3)を用いた実践までを網羅的に解説します。
強化学習の基本概念
強化学習(Reinforcement Learning, RL)は、エージェント(Agent)が環境(Environment)と相互作用し、試行錯誤を通じて最適な行動戦略を学習する機械学習の一分野です。このプロセスにおいて、エージェントは自身が実行した行動の結果として環境から報酬(Reward)を受け取り、その報酬を最大化するように方策(Policy)を改善していきます。強化学習の目的は、累積報酬和(Return)を最大化する方策を見つけることです。
強化学習におけるタスクは、多くの場合、マルコフ決定過程(Markov Decision Process, MDP)として数学的に定式化されます。MDPは、将来の状態の条件付き確率分布が現在の状態にのみ依存するという「マルコフ性」を満たす状態遷移を持つ確率過程のモデルです。MDPは以下の主要な要素から構成されます。
- 状態(State, \(S\)): 環境の現在の状況や配置を表す集合です。エージェントは、この状態の情報に基づいて行動を選択します。
- 行動(Action, \(A\)): エージェントが特定の状態で実行できる選択肢の集合です。
- 報酬(Reward, \(R\)): エージェントが特定の状態 \(S\) で行動 \(A\) を実行したときに、環境から即座に受け取る数値的なフィードバックです。
- 状態遷移確率(Transition Probability, \(P\)): ある状態 \(S\) で行動 \(A\) をとったときに、次の状態 \(S’\) へと環境が遷移する確率を示します。
- 割引率(Discount Factor, \(\gamma\)): 将来得られる報酬を現在の価値に換算するための係数で、0から1の間の値を取ります。この値が大きいほど、エージェントは将来の報酬を重視するようになります。
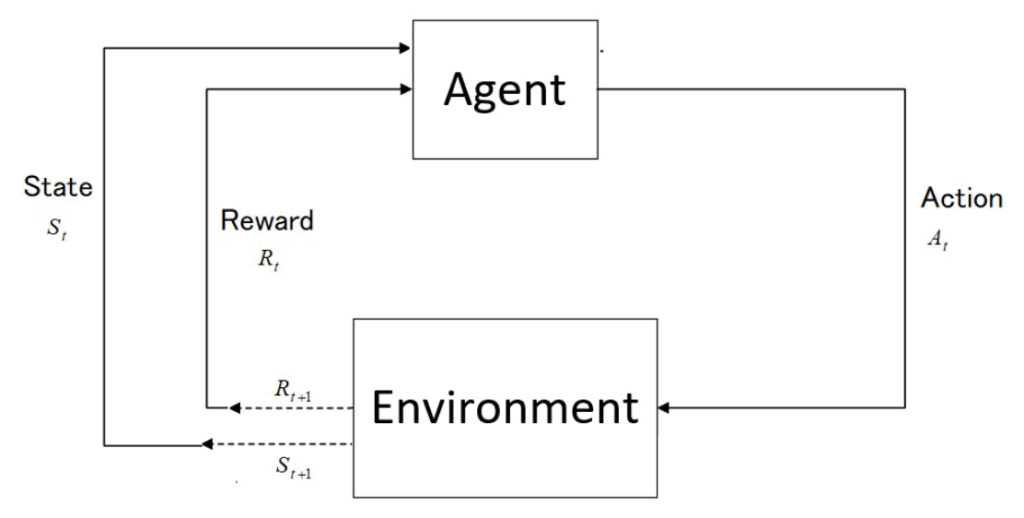
エージェントの行動戦略は方策(Policy, \(\pi\))と呼ばれます。方策は、ある状態 \(S\) においてどの行動 \(A\) を選択するか(または選択する確率)を決定するルールであり、強化学習の究極的な目標は、期待される累積報酬を最大化する最適方策(Optimal Policy, \(\pi^*\))を見つけることです。
エージェントが将来にわたって受け取る割引された累積報酬の合計は収益(Return, \(G\))と定義されます。これは、ある時点からエージェントが獲得するであろうすべての報酬を割引率 \(\gamma\) を考慮して合計したものであり、エージェントの長期的なパフォーマンスを評価する指標となります。
強化学習では、収益を予測するために価値関数(Value Function)という概念が用いられます。価値関数には主に以下の2種類があります。
- 状態価値関数(State-Value Function, \(V^\pi(s)\)): 特定の状態 \(s\) から開始し、現在の方策 \(\pi\) に従って行動を続けた場合にエージェントが期待できる、割引された総報酬の合計です。
- 行動価値関数(Action-Value Function, \(Q^\pi(s,a)\)): 特定の状態 \(s\) で行動 \(a\) をとった後、方策 \(\pi\) に従って行動を続けた場合にエージェントが期待できる、割引された総報酬の合計です。この行動価値関数は、ある状態における各行動の「良さ」を評価するために特に重要です。
これらの価値関数は、ベルマン方程式(Bellman Equation)という再帰的な関係式によって表現されます。ベルマン方程式は、現在の状態や行動の価値が、即時報酬と次の状態の価値(または行動の価値)によってどのように決定されるかを示し、最適方策を導出するための基本的なツールとなります。
古典的な強化学習アルゴリズム
深層強化学習(DRL)の目覚ましい進展は、古典的な強化学習(RL)アルゴリズムによって築かれた基盤の上に成り立っています。このセクションでは、DRLの理解に不可欠な古典的なRLアルゴリズムの基本的な考え方と課題について解説します。
モデルベースとモデルフリー
強化学習アルゴリズムは、環境のモデル(状態遷移確率や報酬関数)を明示的に利用するかどうかで、モデルベース(Model-based)とモデルフリー(Model-free)の2つに大別されます。
- モデルベースRL:環境のダイナミクスを明示的に学習し、そのモデルを利用して最適な行動を計画します。環境の振る舞いが既知であるか、学習によって正確に推定できる場合に有効なアプローチです。
- モデルフリーRL:環境モデルを直接学習せず、エージェントが環境と相互作用して得られる経験から、直接方策(Policy)や価値関数(Value Function)を学習します。環境モデルが不明な場合や、モデル化が困難な複雑な環境で多く用いられます。
価値ベースと方策ベース
エージェントの行動戦略を学習する方法によって、強化学習はさらに価値ベース(Value-based)と方策ベース(Policy-based)に分類されます。
- 価値ベースRL:最適な行動価値関数 \(Q(s, a)\) を推定し、その価値が最大となる行動を貪欲(greedy)に選択することで方策を決定します。代表的なアルゴリズムとしてQ学習(Q-learning)などがあります。
- 方策ベースRL:方策 \(\pi(a|s)\) を直接パラメータ化し、この方策が獲得する期待報酬を最大化するようにパラメータを更新します。行動空間が高次元または連続である場合に特に有効ですが、大域的な最適解に到達しにくく、局所最適解に陥りやすいというデメリットもあります。
探索と活用 (Exploration-Exploitation)
強化学習における重要な課題の一つに、探索と活用(Exploration-Exploitation)のトレードオフがあります。これは、エージェントが「現在知っている最も良い行動(活用)」を選択して報酬を最大化するか、「まだ試していない未知の行動(探索)」を試してより良い報酬を見つけるか、というバランスを取る必要性を指します。
このバランスを取るための一般的な戦略として、\(\varepsilon\)-greedy法(epsilon-greedy method)が挙げられます。\(\varepsilon\)-greedy法では、エージェントは以下のルールに従って行動を選択します。
- 確率 \(\varepsilon\) で、ランダムな行動を選択します。
- 確率 \((1 – \varepsilon)\) で、現在の価値関数に基づいて最適な行動(貪欲な行動)を選択します。
\(\varepsilon\)-greedy法は深層強化学習の文脈でも広く用いられています。
代表的な古典アルゴリズム
ここでは、上記のアプローチに基づいた主要な古典的強化学習アルゴリズムを紹介します。
- 動的計画法(Dynamic Programming, DP) 環境モデル(状態遷移確率と報酬期待値)が完全に既知である場合に、最適な方策を計算するための手法です。
- 方策反復法(Policy Iteration): 方策評価(価値関数の計算)と方策改善(価値関数を最大化する行動への方策更新)の2ステップを交互に繰り返すことで最適な方策を求めます。
- 価値反復法(Value Iteration): 最適ベルマン方程式を逐次代入により数値的に解くことで、方策評価と方策改善を一度に行い、最適な方策を導出します。
- モンテカルロ法(Monte-Carlo method) 環境モデルが不明な場合のモデルフリー手法の一つです。エージェントはエピソードが終了するまで環境と相互作用し、そのエピソードで得られた報酬の合計(収益、Return)を計算します。この収益の平均値を用いて、各状態の価値を推定します。終端状態までサンプリングする必要があるため、オンライン学習には適していません。
- TD学習(Temporal Difference Learning) モンテカルロ法と動的計画法の中間に位置するモデルフリー手法です。エピソードの途中でも、各タイムステップでTD誤差(Temporal Difference error)を計算し、それを用いて価値関数を逐次的に更新します。これにより、オンライン学習が可能となります。
- SARSA(State-Action-Reward-State-Action) 方策オン型(On-policy)のTD学習アルゴリズムです。エージェントは、現在の行動方策に従って選択した行動 \(a_t\)、その結果得られた報酬 \(r_t\)、次の状態 \(s_{t+1}\)、そして次の状態 \(s_{t+1}\) で現在の行動方策に従って選択されるであろう次の行動 \(a_{t+1}\) を基に行動価値関数 \(Q(s_t, a_t)\) を更新します。SARSAでは、\(\varepsilon\)-greedy法などを用いて方策改善を行います。
- Q学習(Q-learning) 方策オフ型(Off-policy)のTD学習アルゴリズムです。Q学習は、エージェントの行動方策(挙動方策、Behavior Policy)とは独立に、最適な行動価値関数 \(Q^*(s, a)\) を学習することを目的とします。現在の状態 \(s_t\) で行動 \(a_t\) を取った後、次の状態 \(s_{t+1}\) で取りうる最大の行動価値(\(\displaystyle \max_a Q(s_{t+1}, a)\))を用いて行動価値関数を更新します。この「最大の行動価値」を用いる点が、方策オン型学習との大きな違いです。Q学習では、行動価値関数が最適行動価値関数に収束することが理論的に証明されています。ただし、深層ニューラルネットワークで近似するDQNなどでは、この厳密な収束性は保証されない場合があることに注意が必要です。Q学習では、過去の経験を再利用して学習効率を高める経験再生(Experience Replay)の手法が提案されています。

深層強化学習の登場
古典的な強化学習手法は、状態空間や行動空間が比較的小規模で明確に定義された環境ではその効果を発揮してきました。しかし、現実世界に見られるような大規模で複雑な問題、例えば高次元の視覚情報を持つゲームやロボット制御タスクなどには、その表現能力と学習効率の限界から対応が困難でした。
この課題を克服するために、深層学習(Deep Learning, DL)が価値関数や方策(Policy)の関数近似器として導入されました。これにより、ニューラルネットワークの強力な表現学習能力と強化学習の意思決定フレームワークが融合し、深層強化学習(Deep Reinforcement Learning, DRL)という新たなパラダイムが誕生しました。DRLは、Atariゲームの高次元な状態表現からコンピュータゲームをプレイしたり、複雑なロボット制御タスクを解決したり、大規模言語モデルをガイドしたりするなど、多岐にわたる分野で顕著な成功を収めています。
DQN (Deep Q-Network)
DQNは、Q学習と深層ニューラルネットワークを組み合わせた画期的なアルゴリズムです。従来のQ学習ではQテーブルを用いて行動価値関数を管理していましたが、DQNでは深層ニューラルネットワーク(DNN)が行動価値関数 $Q(s,a)$ を近似します。これにより、Atariゲームのピクセルデータのような高次元の視覚情報を直接入力として受け取り、そこから意味のある特徴を学習することが可能になりました。DQNの主要な特徴は以下の通りです。
- 経験再生 (Experience Replay): 過去の経験データ(状態、行動、報酬、次の状態の遷移)をリプレイバッファと呼ばれるメモリに保存します。学習時にはこのバッファから経験をランダムにサンプリングして使用することで、連続した経験データに見られる強い相関を低減し、学習の安定性を高めます。
- ターゲットネットワーク (Target Network): Q値の目標値を計算するために、学習中のメインのQネットワークとは別に、固定されたパラメータを持つターゲットネットワークを使用します。このネットワークのパラメータは一定期間ごとにメインネットワークからコピーされるため、学習プロセスがより安定し、目標値が頻繁に変動することによる不安定性を抑制します。
- 報酬クリッピング (Reward Clipping): 報酬の値を例えば-1から1の範囲にクリッピングすることで、報酬のスケールによる学習の不安定化や、一部の過大な報酬が学習に与える影響を防ぎます。
方策勾配法 (Policy Gradient Methods)
方策勾配法は、DNNを用いて方策 \(\pi(a|s)\) を直接パラメータ化し、エージェントが獲得する期待収益を最大化するように方策パラメータを更新する手法です。この方法は、行動空間が高次元または連続である環境においても適用可能であるという大きな利点があります。しかし、一般的に学習の分散が大きく、安定した学習が難しいという課題や、大域的な最適解よりも局所最適解に陥りやすいというデメリットも抱えています。
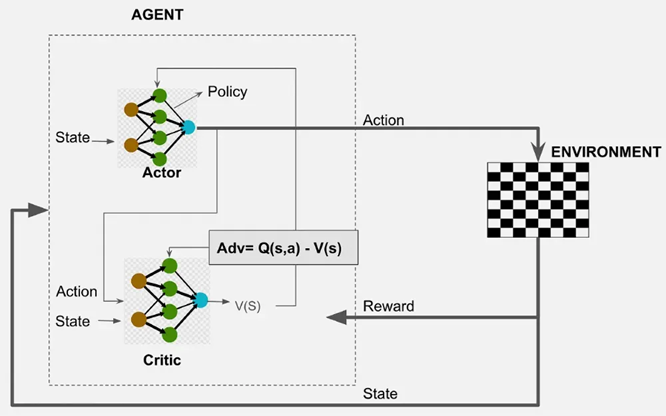
Actor-Critic法
Actor-Critic法は、方策を学習する「Actor」と、価値関数を評価する「Critic」という2つのネットワークを協調させて学習を進める強化学習フレームワークです。
- Criticは、TD誤差(Temporal Difference error)などを用いて、現在の状態や行動の価値を評価します。
- その評価結果は、アドバンテージ関数(Advantage Function)という形でActorにフィードバックされます。このフィードバックを受け、Actorはより良い方策へと更新されます。
Actor-Critic法は、高次元または連続的な行動空間の探索に特に有効であるとされています。代表的なアルゴリズムとしては、非同期的に複数のエージェントがパラメータを共有しながら学習を進めるA3C (Asynchronous Advantage Actor-Critic)や、その同期版であるA2C (Advantage Actor-Critic)などが存在します。
代表的なDRLアルゴリズム
DRLの分野では、上記DQN、方策勾配法、Actor-Criticの発展形として、以下のような多様なアルゴリズムが提案され、それぞれの課題を克服し、性能を向上させてきました。
- PPO (Proximal Policy Optimization): 方策の更新幅を制限する(クリップする)ことで、学習の安定性とサンプル効率を両立させたActor-Criticアルゴリズムです。現在、最も広く利用されているDRLアルゴリズムの一つです。
- DDPG (Deep Deterministic Policy Gradient): 決定論的方策勾配法を深層学習で実装したもので、連続行動空間向けに設計されています。方策が最適行動として決定論的に決まると仮定して学習を進めます。
- SAC (Soft Actor-Critic): 最大エントロピーの原理に基づき、探索(Exploration)と活用(Exploitation)のバランスを保ちつつ、学習の安定性とサンプル効率を高めるオフポリシーアルゴリズムです。
- TD3 (Twin Delayed DDPG): DDPGの課題であったQ値の過大評価バイアスに対処し、学習の安定性をさらに向上させたアルゴリズムです。複数のQ関数と遅延更新を用いることで、このバイアスを軽減します.
- HER (Hindsight Experience Replay): ゴール条件付き強化学習において、エピソードが成功しなかった場合でも、実際に達成された(異なる)ゴールを「新しいゴール」として経験を再利用することで、サンプル効率を大幅に向上させる手法です。
Stable Baselines3による強化学習の実践
強化学習(RL)の分野は、深層学習(DL)の登場により深層強化学習(DRL)として大きく進化し、Atariゲームのピクセルデータのような高次元の視覚情報を直接入力として扱う能力を獲得しました。これにより、古典的な強化学習では困難だった大規模で複雑な問題への適用が可能になりました。しかし、DRLはブラックボックス化しやすいニューラルネットワークに依存するため、解釈性や信頼性、実世界での安全性確保といった課題も抱えています。
このような背景の中で、DRLアルゴリズムを信頼性高く、使いやすい形で提供し、研究者や開発者が効率的に実験し、新しいアイデアを構築できることを目指して開発されたのがStable Baselines3 (SB3)です。SB3は、既存の強化学習アルゴリズムの性能を論文通りに再現できるように丁寧な検証が行われており、安定したベースラインとして広く利用されています。
Stable Baselines3の特徴
Stable Baselines3は、PyTorch上に構築されており、以下のような主要な特徴を持っています。
- 使いやすさ: 多くの強化学習アルゴリズムが統一されたシンプルなAPIで実装されており、複雑な設定なしに利用できます。
sklearnライクな構文を目指しており、直感的に扱えるのが特徴です。 - 信頼性: 論文で発表されているアルゴリズムの性能を再現できるように、その実装は丁寧に検証されており、各アルゴリズムの性能はテスト済みです。これにより、研究の再現性を高め、新しいアプローチの比較対象として信頼できるベースラインを提供します。
- 多様なアルゴリズム: DQN、A2C、PPO、SACなど、主要な深層強化学習アルゴリズムが多数含まれています。これにより、様々な問題設定や環境に対して最適なアルゴリズムを選択できます。
- PyTorchベース: 人気のある深層学習フレームワークであるPyTorch上で動作するため、GPUを活用した高速な学習が可能です。
- カスタマイズ性: アルゴリズムのハイパーパラメータや、モデルのアーキテクチャを細かく調整することができ、独自の環境にも柔軟に対応できます。
- 統合されたツール: 学習プロセスを管理するための便利な機能が組み込まれています。例えば、Tensorboardによる学習ログの記録、モデルの保存・ロード、ハイパーパラメータのチューニングといった機能が提供されています。
- 関連プロジェクト: SB3は安定したコアを維持しつつ、より新しい実験的な機能を提供するSB3-Contribリポジトリ(Recurrent PPOやMaskable PPOなど)や、Jaxベースで高速なSBXリポジトリ(DroQ、CrossQなど)といった関連プロジェクトも展開しています。
主要アルゴリズム
Stable Baselines3は、以下に示すように多様な強化学習アルゴリズムをサポートしています。行動空間の種類(Box、Discrete、MultiDiscrete、MultiBinary)への対応や、マルチプロセッシング、リカレント機能の有無によって、様々な環境に適応できます。
| Name | Recurrent | Box | Discrete | MultiDiscrete | MultiBinary | Multi Processing |
|---|---|---|---|---|---|---|
| ARS* | ❌ | ✔️ | ✔️ | ❌ | ❌ | ✔️ |
| A2C | ❌ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| CrossQ* | ❌ | ✔️ | ❌ | ❌ | ❌ | ✔️ |
| DDPG | ❌ | ✔️ | ❌ | ❌ | ❌ | ✔️ |
| DQN | ❌ | ❌ | ✔️ | ❌ | ❌ | ✔️ |
| HER | ❌ | ✔️ | ✔️ | ❌ | ❌ | ✔️ |
| PPO | ❌ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| QR-DQN* | ❌ | ❌ | ✔️ | ❌ | ❌ | ✔️ |
| RecurrentPPO* | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| SAC | ❌ | ✔️ | ❌ | ❌ | ❌ | ✔️ |
| TD3 | ❌ | ✔️ | ❌ | ❌ | ❌ | ✔️ |
| TQC* | ❌ | ✔️ | ❌ | ❌ | ❌ | ✔️ |
| TRPO* | ❌ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| Maskable PPO* | ❌ | ❌ | ✔️ | ✔️ | ✔️ | ✔️ |
*印のアルゴリズムは、SB3-Contribリポジトリに実装されています。
インストール方法
Stable Baselines3のインストールは非常に簡単です。以下のpipコマンドを使用します。
# 基本パッケージのインストール pip install stable-baselines3 # Tensorboard、OpenCV、Atariゲームのトレーニングに必要な `ale-py` などの # オプション依存関係もインストールする場合 pip install 'stable-baselines3[extra]'
Stable Baselines3はPython 3.9以上とPyTorch 2.3以上のバージョンに対応しています。
実装例
Stable Baselines3を使った強化学習の学習と実行は、数行のコードで実現できます。以下に、CartPole環境でPPOアルゴリズムを学習・実行する例を示します。
PPOを訓練するコード
import gymnasium as gym
from rich import print
from stable_baselines3 import PPO
from stable_baselines3.common.vec_env import DummyVecEnv
from stable_baselines3.common.evaluation import evaluate_policy
# 1. 環境の作成
# ベクトル化された環境を作成します。これは複数の環境を並列で実行するためのラッパーです。
# 今回は1つだけなのでDummyVecEnvを使用します。
env = DummyVecEnv([lambda: gym.make("CartPole-v1")])
# 2. モデルの定義
# PPO (Proximal Policy Optimization) アルゴリズムを使用します。
# "MlpPolicy"は、観測と行動が連続値である標準的なニューラルネットワークポリシーです。
model = PPO("MlpPolicy", env, verbose=1)
# 3. モデルの学習
# total_timestepsで指定されたステップ数だけ学習を実行します。
print("学習を開始します...")
model.learn(total_timesteps=10000)
print("学習が完了しました。")
# 4. 学習済みモデルの評価
# evaluate_policyヘルパー関数を使って、学習済みエージェントのパフォーマンスを評価します。
# n_eval_episodesで指定されたエピソード数だけ評価を実行し、平均報酬と標準偏差を返します。
mean_reward, std_reward = evaluate_policy(model, env, n_eval_episodes=10)
print(f"平均報酬: {mean_reward:.2f} +/- {std_reward:.2f}")
# 5. モデルの保存
model.save("ppo_cartpole")
print("モデルを 'ppo_cartpole.zip' に保存しました。")
# 6. 環境を閉じる
env.close()
print("訓練が完了しました。")
学習済みモデルを利用するコード
import gymnasium as gym
from rich import print
from stable_baselines3 import PPO
# 1. モデルの読み込み
# "ppo_cartpole.zip"から学習済みモデルを読み込みます。
try:
model = PPO.load("ppo_cartpole")
print("モデル 'ppo_cartpole.zip' を読み込みました。")
except FileNotFoundError:
print("エラー: 'ppo_cartpole.zip' が見つかりません。")
print("まず 'train.py' を実行してモデルを訓練・保存してください。")
exit()
# 2. 学習済みエージェントの動作を確認
# 環境を可視化するために、render_modeを"human"に設定して新しい環境を作成します。
print("学習済みエージェントの動作を確認します。")
eval_env = gym.make("CartPole-v1", render_mode="human")
obs, info = eval_env.reset()
for _ in range(1000):
action, _states = model.predict(obs, deterministic=True)
obs, reward, terminated, truncated, info = eval_env.step(action)
eval_env.render()
# エピソードが終了したらリセット
if terminated or truncated:
print("エピソード完了。リセットします。")
obs, info = eval_env.reset()
# 3. 環境を閉じる
eval_env.close()
print("実行が完了しました。")
Stable Baselines3は、このようにシンプルなAPIと豊富なアルゴリズム群、そして高い信頼性によって、強化学習の研究・開発、そして学習において強力なツールとなっています。強化学習の知識は前提とされますが、そのフレームワークは初心者でも高度なアルゴリズムを容易に利用できる設計となっています。
実世界への応用と最新トレンド
深層強化学習(DRL)は、その強力な能力により、ゲームやロボティクス、さらには大規模言語モデル(LLM)の分野に至るまで、多様な実世界の問題解決に適用され始めています。このセクションでは、DRLの主要な応用分野と、その最先端のトレンドを概観します。
ロボティクスへの応用
DRLは、ロボットが歩行、操作、ナビゲーション、人間とのインタラクションといった高度な行動を学習する上で、大きな可能性を秘めています。しかし、物理世界とのインタラクションの複雑さやコストが課題となります。
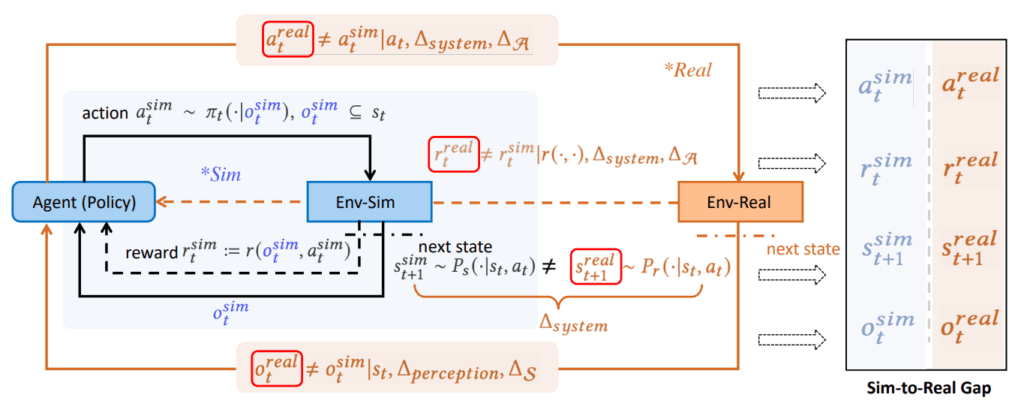
Sim-to-Real問題とギャップ克服技術
実世界でのロボット学習は非効率的かつ危険な場合が多いため、シミュレーション環境で学習したポリシーを実世界のロボットに転移させる「Sim-to-Real」は極めて重要な研究テーマです。この際、シミュレータと実世界との間のギャップ(sim-to-real gap)が問題となり、これを埋めるための様々な技術が研究されています。 例えば、四足歩行ロボットの分野では、ゼロショットsim-to-real転送が最も成熟したDRLソリューションの一つであり、動力学パラメータのランダム化や、低レベルのモデルベースコントローラとDRLポリシーを組み合わせる階層構造の採用によって、リアリティギャップを埋める努力がされています。一方で、二足歩行ロボットは不安定な動力学特性を持つため、シミュレーションから実世界への転送が主流ですが、ロボットの回復能力の限界から実世界での直接学習は限られています。
主要なロボット能力とDRLの貢献
DRLは、以下のような多岐にわたるロボット能力の実現に貢献しています。
- 移動制御(Locomotion):
- 四足歩行ロボットは、DRLが実世界で成熟したソリューションを提供している代表的な分野であり、ANYbotics、Swiss-Mile、Boston Dynamicsといったロボット企業がDRLを制御に統合しています。DRL手法は、当初は平坦な屋内で盲目的な歩行(プロプリオセプティブセンサーのみに依存)のために検証され、その後、不連続な表面、変形可能な表面、滑りやすい表面といった困難な地形にも対応できるよう進化しています。
- 二足歩行ロボットの移動制御は、非静的に安定した動力学のため、基本的な立ち方や歩行の学習からして困難を伴います。ここでは、モデルベースのアプローチ、状態や行動の「記憶」を考慮したシーケンスモデル(RNNなど)、参照不要な周期的報酬設計などが活用されています。
- 操作(Manipulation):
- 把持(Grasping)は、DRLが大規模な成功を収めた初期の分野の一つで、未知の形状や外観の物体を把持する能力を実現しました。多くの研究では、把持をバンディット問題や分類問題として定式化し、スパース報酬と自己教師ありデータ収集を用いて学習が行われます。シミュレーションでのデータ収集が一般的な手法です。
- エンドツーエンドのピックアンドプレースは、物体の多様性やタスクの複雑さから、現在のアルゴリズムの汎化能力の限界に直面しており、開かれた世界での汎用的な実現は依然として困難です。多重タスク学習、サンプル効率の向上、報酬関数の設計、環境のリセット、人間によるデモンストレーション、オフラインデータ、そして大規模ビジョン言語モデルの活用などが研究されています。
- 組立(Assembly)は製造業で重要ですが、DRLの産業分野での普及は限定的です。しかし、sim-to-real転送や人間によるデモンストレーションを活用した成功例も報告されており、DRLベースのポリシーが摂動に対してより頑健である可能性が示されています。
- ナビゲーション(Navigation):
- 視覚ナビゲーションは、視覚情報を基に目標地点へ移動する問題で、DRLは視覚的にリアルなシミュレーション環境で高い性能を示していますが、実世界への転送は課題が多いです。マッピングやプランニングモジュールを持たないエンドツーエンド手法と、DRLをグローバル探索ポリシーとして活用するモジュール型設計が研究されています。
- 自動運転においては、DRLの実世界での成功は限定的であり、安全性、説明可能性、汎化能力の面で課題が残されています。特定の条件下での車線維持やクルーズコントロールへの適用例が報告されています。
- ヒューマンロボットインタラクション(HRI):
- DRLはHRIにおいて、他のロボット領域に比べて成功例が少ない状況です。これは、人間または人間のような事前知識を学習プロセスに適切に組み込むことが主要な課題であるためです。特に、人間が積極的に関与する協調的HRIタスクでは、オンラインでのインタラクションデータ収集コストが高いため、人間モデルをシミュレーションで学習したり、人間の行動をハードコーディングしたりするアプローチが取られています。
リアルワールド成功レベル
DRLの実世界での実用性を評価するため、「リアルワールド成功レベル」という指標が提案されています。これは、レベル0(シミュレーションのみ)からレベル5(商業製品に展開)までの6段階でDRLソリューションの成熟度を定量化するもので、研究プロトタイプと実世界展開とのギャップを評価することを目的としています。
大規模言語モデル(LLM)とRL
RLは、大規模言語モデル(LLM)の性能と人間の選好との整合性(アライメント)を高めるために不可欠な役割を果たしています。
- RLHF (Reinforcement Learning from Human Feedback):
- RLHFは、人間のフィードバック(評価や選好)を報酬信号として利用し、LLMの出力を人間の期待や倫理的ガイドラインに沿うようにファインチューニングする、極めて重要な手法です。
- このプロセスにより、LLMは事実の正確性、一貫性、ユーザー満足度といった属性を最適化することができ、従来の教師あり学習手法を超える成果を上げています。PPO、DPO(Direct Preference Optimization)、RAFT(Reward rAnked FineTuning)などのRLアルゴリズムが、LLMのファインチューニングに活用されています。
- しかし、LLMの複雑さとRLの逐次的な意思決定の組み合わせは、説明可能性の課題をさらに増幅させます。RLの更新がニューラル表現にどのように影響するか、また、入力データがモデルの出力生成にどう影響するかを解釈することは依然として困難です。
説明可能なDRL (Explainable Reinforcement Learning, XRL)
DRLエージェントが深層ニューラルネットワークに依存する「ブラックボックス」モデルとして動作するため、その意思決定プロセスが不透明であるという根本的な課題があります。この不透明性は、信頼性、デバッグ、高リスクなアプリケーション(医療、自動運転、金融リスク評価など)での展開を阻害します。 説明可能なDRL(XRL)は、これらの課題に対処し、DRLポリシーの解釈性を高めることを目的とした分野です。XRLは、エージェントの推論を理解するための洞察を提供することで、より安全で、より堅牢で、倫理的に整合性の取れたAIシステムの開発に貢献します。
説明手法のカテゴリ
XRLの手法は、主に以下の4つのカテゴリに分類されます。
- 特徴量レベル説明(Feature-level Explanation):
- エージェントの観測空間において、その意思決定に影響を与える最も重要な特徴(例:ピクセル)を特定することに焦点を当てます。視覚入力の処理を理解するのに特に有用です。
- 摂動ベース手法(入力を摂動させてポリシーの変化を観察)や勾配ベース手法(ポリシーや価値関数の勾配を利用)、アテンションベース手法(エージェントがタスク関連情報に焦点を当てるメカニズム)などがあります。
- 状態レベル説明(State-level Explanation):
- RLの軌跡の中で、最も重要な意思決定の瞬間(クリティカルなステップ)を識別します。これは、RLエージェントのデバッグや改善に特に役立ちます。
- オフライン軌跡分析(事前収集された軌跡から説明モデルを近似)やオンラインインタラクション(エージェントの行動中に重要度を検出)に基づく手法があります。
- データセットレベル説明(Dataset-level Explanation):
- 特定のトレーニング例がRLエージェントの学習済みポリシーにどのように影響するかを理解することに焦点を当てます。訓練の非効率性の診断、有害な経験の検出、データ収集戦略の改善に貢献します。
- 「影響関数(Influence Functions)」は、単一のトレーニング例がモデルパラメータに与える影響を推定する手法として広く利用されます。ただし、LLMの文脈ではその性能に限界があることも指摘されています。
- モデルレベル説明(Model-level Explanation):
- RLポリシーモデルの自己説明可能性に焦点を当て、エージェントの意思決定プロセスを本質的に解釈可能にすることを目指します。
- 透明なアーキテクチャ(例:決定木)や、エージェントのポリシーから人間が理解できるルールを抽出する手法が含まれます。医療や自動運転のように高い透明性が要求されるアプリケーションで特に価値があります。
メタ強化学習 (Meta-Reinforcement Learning, Meta-RL)
メタ強化学習は、「学習する方法」自体を学習することを目指す分野です。具体的には、複数の環境やタスクの分布から学習することで、新しい未見のタスクに素早く適応できるエージェントの構築を目指します。 これにより、DRLポリシーは、時間とともに変化する環境や異なるタスクに対して、汎化能力を大幅に向上させることが可能になります。メタ強化学習の目的は、エージェントが長期にわたって学習し、変化するMDPの条件に適応できるようにすることです。これは、RLアルゴリズムの自動発見(AutoRL)とも関連する分野であり、学習アルゴリズム自体の更新ルールを最適化することにも焦点を当てています。
構造化強化学習 (Structured Reinforcement Learning)
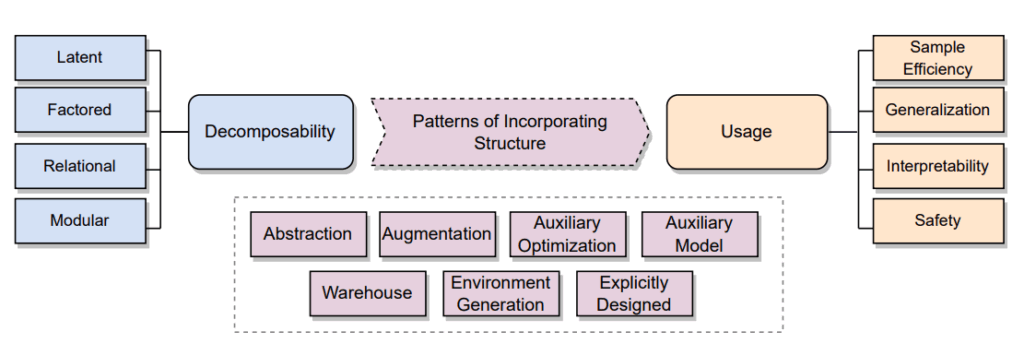
構造化強化学習は、マルコフ決定プロセス(MDP)や方策の構造情報(例:状態空間、行動空間、報酬関数、環境ダイナミクスに関する事前知識)を明示的に強化学習の学習プロセスに組み込むことで、サンプル効率、汎化、説明可能性、安全性を向上させるアプローチです。これは、DRLが抱えるデータ効率の悪さ、汎化能力の限界、安全性保証の欠如、解釈性の不足といった根本的な課題を克服するために重要とされています。
構造の分解タイプ
学習問題における構造は、以下の4つの主要な分解タイプとして捉えることができます。
- 潜在的分解(Latent Decomposition):
- 環境の基盤となる構造が不明瞭または非定常な場合に有効です。状態、行動、遷移、報酬などのパイプライン構成要素を潜在表現で近似し、学習プロセスに組み込みます。
- 要因化分解(Factored Decomposition):
- パイプライン構成要素を複数の因子(latent factors)で表現し、これらの因子が学習ダイナミクスに条件付き独立性を課すことで影響を与える手法です。状態、行動、報酬において利用されます。
- 関係性分解(Relational Decomposition):
- 単に因子を表現するだけでなく、異なる因子間の相互作用(関係性)に関する情報を活用します。エンティティ間の関係性を捉え、グラフ構造を通じて表現されることが多く、汎化能力の向上に貢献します。
- モジュール化分解(Modular Decomposition):
- 分解された個々のエンティティ(サブシステム)に対して、モデル、価値関数、ポリシーを独立して学習することを可能にします。空間的、時間的、機能的なモジュール性が存在し、特に階層型強化学習(HRL)で頻繁に利用されます。
構造組み込みの7つのパターン
構造情報をRL学習パイプラインに組み込むための戦略は、以下の7つのパターンに分類されます。
- 抽象化パターン(Abstraction Pattern):
- 構造情報を利用して抽象的なエンティティ(例:抽象化された状態空間や行動空間)を作成し、学習手順においてその役割を引き継がせることで、問題の複雑さを軽減し、サンプル効率を向上させます。
- 拡張パターン(Augmentation Pattern):
- 構造情報を、状態や行動などの既存のエンティティへの追加入力として扱います。抽象化された情報が補助的な入力として追加される場合も含まれます。
- 補助最適化パターン(Auxiliary Optimization Pattern):
- 構造情報を用いて最適化手順自体を変更します。これには、対照学習、報酬整形、同時最適化、マスキング戦略、正則化などが含まれ、サンプル効率や汎化に貢献します。
- 補助モデルパターン(Auxiliary Model Pattern):
- 構造情報を環境モデルなどの補助モデルに組み込み、学習経験の一部または全体を生成するために利用します。これにより、モデルベースRLにおける効率性と汎化能力を高めます。
- ポートフォリオパターン(Portfolio/Warehouse Pattern):
- 学習済みのポリシー、価値関数、モデル、またはそれらの構成要素を保存し、新しいタスクや環境に再利用します。モジュール化されたスキル群や共有潜在パラメータを活用し、継続学習やマルチタスク学習での効率性と汎化を促進します。
- 環境生成パターン(Environment Generation Pattern):
- 構造情報を使用して、多様なタスク、目標、またはダイナミクスの分布を生成し、そこからMDPをサンプリングして学習に利用します。カリキュラム学習やドメインランダム化を通じて汎化能力を向上させます。
- 明示的設計パターン(Explicitly Designed Pattern):
- ニューラルネットワークアーキテクチャやアルゴリズム自体に、畳み込み層、モジュール、関係性バイアスといった構造情報を明示的に組み込むことで、解釈可能性や汎化能力を高めます。特に、階層的なアーキテクチャや不変性を捉える設計が含まれます。
おわりに
今回は、強化学習の基礎から深層強化学習(DRL)の主要アルゴリズム(DQN、PPOなど)を概観し、いくつかの応用例を紹介しました。DRLはAIシステムの可能性を大きく広げましたが、実世界への展開には依然として多くの課題が残されています。
具体的には、汎化能力の向上、データ効率の改善、学習の安定化、そして説明可能性や安全性の確保が重要です。これらの課題に対処するため、研究は探索戦略の改善(例: ε-greedy、NoisyNet)、多様な正則化技術(データ拡張、関数正則化)、敵対的学習、Meta-RL、XRL、そして構造化RL(潜在的、因数分解、関係性、モジュール分解に基づく)といった多角的なアプローチで活発に進められています。
また実務者にとって、これらの基本原理の理解とStable Baselines3のような実践的なライブラリの活用は、現実世界の複雑な問題に応用する上で必要不可欠です。今後、強化学習は自律システムや高度なAIシステムの構築において中心的な役割を果たすと期待されており、その基礎と最先端の知見を常に学び続けることが重要になります。
More Information
- arXiv:2306.16021, Aditya Mohan et al., 「Structure in Deep Reinforcement Learning: A Survey and Open Problems」, https://arxiv.org/abs/2306.16021
- arXiv:2401.02349, Ezgi Korkmaz, 「A Survey Analyzing Generalization in Deep Reinforcement Learning」, https://arxiv.org/abs/2401.02349
- arXiv:2408.03539, Chen Tang et al., 「Deep Reinforcement Learning for Robotics: A Survey of Real-World Successes」, https://arxiv.org/abs/2408.03539
- arXiv:2502.06869, Zelei Cheng et al., 「A Survey on Explainable Deep Reinforcement Learning」, https://arxiv.org/abs/2502.06869
- arXiv:2502.13187, Longchao Da et al., 「A Survey of Sim-to-Real Methods in RL: Progress, Prospects and Challenges with Foundation Models」, https://arxiv.org/abs/2502.13187
関連記事

Qwen3-TTS: 思い通りの声を創り出すAI音声合成
Qwenチーム(Alibaba Cloud)は、最新の多言語対応音声合成(TTS)モデルシリーズ「Qwen3-TTS」を公開しました。本モデルは500万時間以上という圧倒的な規模の音声データで学習され、日本語を含む10言 […]

LiteASR: 低ランク近似による効率的な自動音声認識の実現
近年、OpenAIのWhisperに代表される大規模な自動音声認識(ASR)モデルが目覚ましい発展を遂げていますが、その計算コストの高さが実用上の課題となっています。特に、リアルタイム処理やリソース制約のある環境での利用 […]

画像認識アーキテクチャの進化大全: CNN・ViT・Mamba・MLPの比較
AI技術の急速な進歩により、画像認識は私たちの生活に深く浸透し、顔認証、自動運転、医療画像診断など、多岐にわたる分野で革新をもたらしています。この画像認識技術の発展を支えているのが、ディープラーニングにおけるモデルアーキ […]