Qwen3-TTS: 思い通りの声を創り出すAI音声合成

Qwenチーム(Alibaba Cloud)は、最新の多言語対応音声合成(TTS)モデルシリーズ「Qwen3-TTS」を公開しました。本モデルは500万時間以上という圧倒的な規模の音声データで学習され、日本語を含む10言語に対応しています。
Qwen3-TTSの最大の特徴は、「ゼロショットでのボイスクローニング」「自然言語による音声スタイルの制御(Voice Design)」、そして「リアルタイム対話に耐えうる低遅延ストリーミング生成」という、従来は個別のモデルで対応していた高度なタスクを、単一のフレームワークで実現している点にあります。特にストリーミング生成においては、最初の音声パケット送出までわずか100ms未満(0.6Bモデル)という極めて低いレイテンシを達成しており、LLMとの統合においても強力な威力を発揮します。
本記事では、Qwen3-TTSの技術的なアーキテクチャの概要に加え、Pythonを用いた具体的な実装コードや、用途に応じたモデルの使い分けについて解説します。
1. Qwen3-TTSの技術的特徴とアーキテクチャ
本セクションでは、Qwen3-TTSがどのように高品質な音声生成とリアルタイム性を両立しているか、その核となるアーキテクチャについて解説します。
アーキテクチャの概要
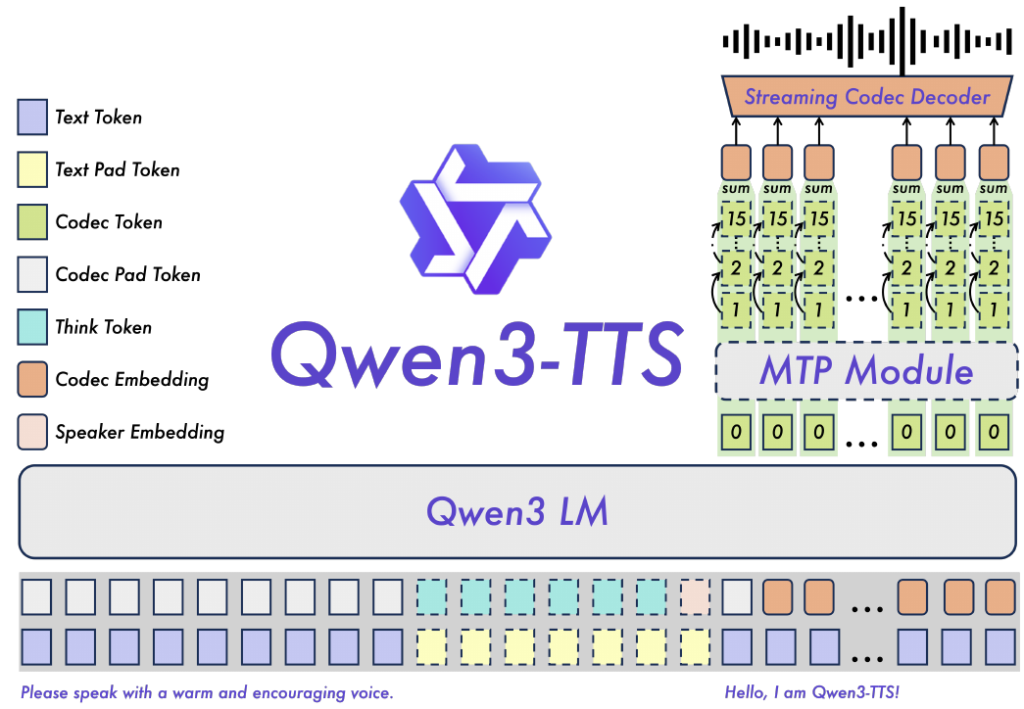
Qwen3-TTSの基盤となっているのは、テキストトークンと音声トークンを統合して処理する「デュアルトラック言語モデル(Dual-track LM)」アーキテクチャです。この設計により、テキスト入力に対して即座に対応する音響トークンを予測することが可能となり、従来のパイプライン処理で発生しがちなボトルネックを解消しています。
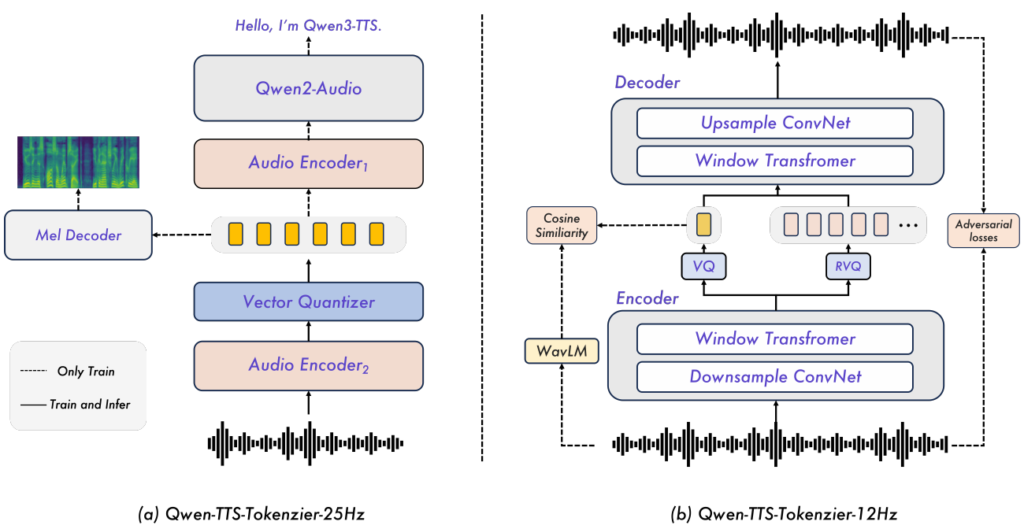
2種類のトークナイザによる最適化
本モデルの最大の特徴は、開発者が「品質(意味理解)」と「速度(低遅延)」のトレードオフを制御できるよう、全く異なる設計思想を持つ2つのトークナイザを提供している点です。
- Qwen-TTS-Tokenizer-25Hz (品質・意味理解重視): 意味情報と音響情報のバランスを重視したシングルコードブック設計です。波形再構成にはフロー・マッチング(Flow Matching)を用いたDiffusion Transformer (DiT) を採用しています。ブロック単位での処理が必要なため極限の低遅延には向きませんが、非常に高品質で表現力豊かな音声生成を実現します。
- Qwen-TTS-Tokenizer-12Hz (超低遅延・ストリーミング重視): リアルタイム対話システムのために、レイテンシを極限まで削ぎ落とした設計です。12.5Hzという低いフレームレートで、複数のコードブック(Multi-codebook)を用いて情報を圧縮します。デコーダには拡散モデルではなく、軽量な因果的畳み込みネットワーク(Causal ConvNet)を採用することで、計算コストを抑えつつ、First-packet latency(最初の音声パケット生成までの遅延)97msを実現しています。
Multi-Token Prediction (MTP)
特に12Hzモデルにおいては、複数のコードブック階層(意味情報から音響詳細まで)を効率的に予測するために、MTPモジュールが組み込まれています。これにより、すべての階層の予測完了を待つことなく、最初のコーデックフレームから即座に音声をデコードすることが可能となり、人間との自然な対話テンポを実現しています。
2. 利用可能な実装リソース
2.1 モデル一覧
現在、GitHubおよびHugging Face/ModelScope等で公開されているQwen3-TTSシリーズの主要なモデル構成は以下の通りです。
特に注目すべき点は、前述した「12Hzトークナイザ」をベースにしたモデル群が先行してリリースされていることです。これにより、開発者は初期段階から超低遅延ストリーミングの恩恵を受けることができます。用途(CustomVoice/VoiceDesign/Base)やパラメータサイズ(1.7B/0.6B)に応じて、最適なモデルを選択してください。
| モデル名 | 説明 | 主な特徴 |
|---|---|---|
| Qwen3-TTS-Tokenizer-12Hz | 音声波形を離散的なコードにエンコードし、再び音声にデコードするためのトークナイザ単体モデル。 | 高圧縮・低遅延・ストリーミング対応 |
| Qwen3-TTS-12Hz-1.7B-VoiceDesign | ユーザーが入力した自然言語の記述(プロンプト)に基づいて、ゼロから新しい声質やスタイルを生成するモデル。 | 音声の新規デザイン(生成) |
| Qwen3-TTS-12Hz-1.7B-CustomVoice | 9種類の高品質なプリセット話者を搭載し、スタイル制御を提供するモデル。特定のキャラクター性を維持したまま、感情や話し方の調整が可能。 | プリセット話者の制御・多言語対応 |
| Qwen3-TTS-12Hz-1.7B-Base | わずか3秒間の参照音声からのボイスクローニング(Zero-shot)に対応したベースモデル。特定のデータセットを用いたファインチューニングの基盤としても利用される。 | ボイスクローニング・追加学習用 |
| Qwen3-TTS-12Hz-0.6B-CustomVoice | 1.7B版と同様にプリセット話者の制御が可能だが、パラメータ数を抑えた軽量版。リソース制約のある環境向け。 | 軽量・プリセット制御 |
| Qwen3-TTS-12Hz-0.6B-Base | 1.7B版と同様の機能を持つ軽量版。ボイスクローニングおよびファインチューニング用。 | 軽量・ボイスクローニング |
2.2 Speaker一覧
CustomVoiceモデルでは、以下のプリセット話者が利用可能です。これらは単なる「サンプルボイス」ではなく、性別、年齢、方言などの特徴が細かくモデリングされています。
また、Qwen3-TTSの強力な多言語能力により、各話者はネイティブ言語以外(例:中国語話者のVivianに英語や日本語を話させる)の生成も自然に行うことができます。
| Speaker | 性別・特徴 | ネイティブ言語 |
|---|---|---|
| Vivian | 明るく、少しエッジの効いた若い女性の声 | 中国語 |
| Serena | 暖かく、優しい若い女性の声 | 中国語 |
| Uncle_Fu | 落ち着いた、芳醇な響きの年配男性の声 | 中国語 |
| Dylan | クリアで自然な北京訛りの若い男性の声 | 中国語(北京方言) |
| Eric | 活気のある、少しかすれた明るい成都訛りの男性の声 | 中国語(四川方言) |
| Ryan | リズミカルでダイナミックな男性の声 | 英語 |
| Aiden | クリアな中音域を持つ明るいアメリカ人男性の声 | 英語 |
| Ono_Anna | 軽快で敏捷な響きの遊び心のある女性の声 | 日本語 |
| Sohee | 豊かな感情表現を持つ温かい女性の声 | 韓国語 |
3. Qwen3-TTSのPython実装
Qwen3-TTSは、単なるテキスト読み上げ(TTS)にとどまらず、多様な音声生成タスクに対応しています。ここでは、開発者がアプリケーションに組み込む際の主要な5つのユースケースについて解説します。
3.1 環境構築とデプロイ
公式ドキュメントではPython 3.12環境での利用が推奨されており、PyPIで公開されているqwen-ttsパッケージ経由で容易に導入できます。
また、推論エンジンとしてvLLMもサポートされており、オフライン推論や、将来的にはオンラインサービングの最適化も期待されています。GPUメモリ効率と推論速度を最大化するためには、FlashAttention 2の利用が強く推奨されます。
セットアップコマンド:
# 基本パッケージのインストール pip install -U qwen-tts # GPUメモリ効率化のためのFlashAttention 2 (推奨) # ※事前にPyTorch等がインストールされたCUDA環境が必要です pip install -U flash-attn --no-build-isolation
3.2 Custom Voice Generate(プリセット話者による生成)
事前に定義された高品質な話者(Speaker)を選択し、テキストから音声を生成する最も基本的な利用法です。
Qwen3-TTSの強力な点は、単にテキストを読み上げるだけでなく、instructパラメータを用いて「怒った口調で」「ニュースキャスターのように」といった感情やスタイルの指定が可能な点にあります。また、多言語モデルであるため、languageパラメータを「Auto」に設定することで入力テキストの言語を自動判別させることも可能です。
以下のコードは、1.7BのCustomVoiceモデルをロードし、日本語プリセット話者である「Ono_Anna」を用いて、特定のニュース原稿風テキストを読み上げさせる例です。このコードを実行すると、指定したスタイル(ニュース原稿調)が反映された音声ファイルが出力されます。バッチ処理を行いたい場合は、text, language, speaker などをリスト形式で渡すことで、複数の音声を一度に生成することも可能です。
import torch
import soundfile as sf
from qwen_tts import Qwen3TTSModel
# 1. モデルのロード
# 利用目的に応じてモデルを選択します。ここではプリセット話者制御用の "CustomVoice" モデルを使用。
model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice",
device_map="cuda:0", # 利用するGPUデバイスを指定
dtype=torch.bfloat16, # 推論精度 (bfloat16推奨)
attn_implementation="flash_attention_2", # FlashAttention 2 を有効化
)
# 2. 音声生成の実行 (Single Inference)
# generate_custom_voice メソッドでテキストから波形を生成します。
wavs, sr = model.generate_custom_voice(
text="実験の結果、被験者らは「権威に訴えかける論法」よりも「矛盾した証拠」に基づく主張を、より質が高いと評価する傾向が確認されました。",
language="Japanese", # 言語指定: "Auto" (または省略) で自動判定も可能ですが、明示的な指定を推奨します。
speaker="Ono_Anna", # 話者指定: 日本語ネイティブの女性話者 "Ono_Anna" を選択。
instruct="ニュースの原稿を読み上げる口調で話す", # スタイル指示: 感情や話し方のトーンを自然言語で指定可能 (省略可)。
)
# 3. 結果の保存
# 生成された音声データ (wavs) をファイルに書き出します。
sf.write("output_custom_voice.wav", wavs, sr)
3.3 Voice Design(プロンプトによる音声デザイン)
通常、特定のキャラクターの声を合成するには、その人の音声データ(参照音声)が必要です。しかし、Qwen3-TTSの Voice Design 機能を使用すれば、参照音声が一切ない状態から、自然言語の記述(プロンプト)だけで全く新しい声を創出することができます。
この機能は、ゲームのNPC(Non-Player Character)や小説の朗読、バーチャルアシスタントなど、「具体的な声優は決まっていないが、明確なキャラクター像がある」ケースに最適です。開発者はinstructパラメータに「性別」「年齢」「音域」「話し方のニュアンス」などを詳細に記述することで、モデルにその特性を想像させ、生成音声をコントロールします。
以下は、VoiceDesign専用モデルを用いて、詳細なキャラクター設定に基づいた音声を生成するコード例です。この例のように、「やや過剰で作為的ながらも」といった複雑なニュアンスを含む指示であっても、モデルはその意図を汲み取って音声に反映させます。これにより、単なる読み上げではない「演技」に近い音声合成が可能となります。
import torch
import soundfile as sf
from qwen_tts import Qwen3TTSModel
# 1. Voice Design専用モデルのロード
# 通常のTTSモデルとは異なり、プロンプト追従性に特化した "VoiceDesign" モデルを使用します。
model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign",
device_map="cuda:0",
dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
# 2. 音声デザインと生成の実行
# generate_voice_design メソッドを使用します。
# 参照音声(ref_audio)は不要です。代わりに `instruct` で声の特徴を定義します。
wavs, sr = model.generate_voice_design(
text="お兄ちゃん、帰ってきたのね!ずっと待ってたの。ぎゅっと抱きしめてほしいな。",
language="Japanese",
# instruct: ここに音声の「デザイン書」を自然言語で記述します。
# 物理的な特徴(音程、性別)だけでなく、抽象的な雰囲気(作為的、愛らしいなど)も反映されます。
instruct="その声は、可憐で無邪気な少女を思わせるもので、高めの音程に加えてはっきりとした抑揚があり、やや過剰で作為的ながらも、愛らしい印象を与える響きを生み出している。",
)
# 3. 結果の保存
sf.write("output_voice_design.wav", wavs, sr)
3.4 Voice Clone(ボイスクローニング)
特定の個人の声を再現したい場合、数時間もの学習データを用意してファインチューニングを行うのはコストがかかります。Qwen3-TTSの Voice Clone 機能は、わずか3秒程度の短い参照音声(Reference Audio)を与えるだけで、その声質や話し方の特徴を捉え、任意のテキストを喋らせる「ゼロショット合成」を実現します。
このタスクには Base モデルを使用します。最も高品質な結果を得るためには、参照音声に加えて、その音声の内容を表す「書き起こしテキスト(Reference Text)」を同時に与えることが推奨されます。これにより、モデルは「何と言っているか(言語情報)」と「どう言っているか(音響情報)」を明確に分離でき、より正確な韻律の再現が可能になります。
以下は、10秒程度の音声ファイル(ずんだもん)とその書き起こしテキストを用いて、ターゲット話者の声で新しい文章を生成するコード例です。なお、参照音声の書き起こしテキストが存在しない場合は、x_vector_only_mode=True オプションを使用することで、話者の特徴ベクトル(Speaker Embedding)のみを用いたクローニングも可能です。ただし、テキストを併用する場合と比較して、韻律の再現性や品質が低下する可能性がある点には留意してください。
import torch
import soundfile as sf
from qwen_tts import Qwen3TTSModel
# 1. Baseモデルのロード
# クローニング(Zero-shot)やファインチューニングの基盤となる "Base" モデルを使用します。
model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-Base",
device_map="cuda:0",
dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
# 2. 参照音声データの準備
# クローン元となる音声ファイルを読み込みます。
# ref_audio は (numpy_array, sample_rate) のタプル形式、またはファイルパスやURLでも指定可能です。
ref_audio, sr = sf.read('reference_sound.wav')
# 参照音声の内容(書き起こし)。これを指定することで、声質の特徴抽出精度が向上します。
ref_text = "Text-to-Speechとは、入力した文字情報をコンピューターが自動的に音声へ変換する技術のことなのだ。"
# 3. ボイスクローニングの実行
wavs, sr = model.generate_voice_clone(
text="情報幾何学とは、確率分布を要素とする統計モデルに関する微分幾何学的研究のことを指します",
language="Japanese",
ref_audio=(ref_audio, sr), # 参照音声
ref_text=ref_text, # 参照テキスト
)
# 4. 結果の保存
sf.write("output_voice_clone.wav", wavs, sr)
3.5 Voice Design then Clone(デザイン後の固定化と再利用)
「Voice Design」機能を使えば、プロンプトから魅力的なキャラクターボイスを生成できますが、生成のたびに微妙なニュアンスが変わってしまったり、毎回デザインプロセスを経るのは計算コストの観点から非効率な場合があります。
そこで推奨されるのが、Voice Designで生成した音声を「正解データ」として固定し、Voice Clone機能で運用するというハイブリッドなワークフローです。
具体的には、まずVoice Designモデルで理想的な「参照音声(Reference Audio)」を作成し、次にBaseモデルを用いてその特徴量を抽出・保存します。これにより、同一のキャラクター性を維持したまま、新しいテキストを次々と読み上げさせることが可能になります。
以下は、テキストプロンプトから架空の男性キャラクターを生成し、その声を「固定化」して別のセリフを喋らせるコード例です。このアプローチを採用することで、ゲームのNPCやバーチャルアシスタントなど、特定のペルソナを一貫して保つ必要があるアプリケーションにおいて、安定した品質の音声を効率的に生成し続けることができます。
import torch
import soundfile as sf
from qwen_tts import Qwen3TTSModel
# 1. Voice Designモデルで「理想の声」を作成する
# まずはプロンプトに従って、キャラクターのベースとなる音声を生成します。
design_model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign",
device_map="cuda:0",
dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
ref_text = "もしかしなんだけど...間違ってたらごめん...その嫉妬って、俺に対する恋愛感情か何かか?"
ref_instruct = "若い男性の声で、落ち着いたトーンで話すが、緊張すると少し声が裏返る。"
# この生成結果(ref_wavs)が、このキャラクターの「声の種」になります。
ref_wavs, sr = design_model.generate_voice_design(
text=ref_text,
language="Japanese",
instruct=ref_instruct
)
# 生成された参照音声を保存(確認用および将来の再利用のため)
sf.write("voice_design_reference.wav", ref_wavs, sr)
# 2. Baseモデルで声を「固定化(Clone Prompt化)」する
# 生成には "Base" モデルを使用します。ここでメモリ節約のためdesign_modelをアンロードすることも検討してください。
clone_model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-Base",
device_map="cuda:0",
dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
# create_voice_clone_prompt を使用して、音声の特徴量を抽出・キャッシュします。
# これにより、推論のたびに音声を解析するコストを削減できます。
voice_clone_prompt = clone_model.create_voice_clone_prompt(
ref_audio=(ref_wavs, sr), # 保存したファイルパスを指定してもOK
ref_text=ref_text, # 参照音声の内容(書き起こし)も渡します
)
# 3. 固定された声で新しいセリフを生成
# voice_clone_prompt を渡すことで、先ほど生成したキャラクターの声で喋らせます。
wavs, sr = clone_model.generate_voice_clone(
text="いけない子猫ちゃんだなぁ。もう悪さしないように見張っておかないと。覚悟しな。",
language="Japanese",
voice_clone_prompt=voice_clone_prompt,
)
sf.write("output_voice_design_them_clone.wav", wavs, sr)
3.6 Tokenizer Encode and Decode(音声の圧縮・伝送)
Qwen3-TTSのトークナイザ(特に Qwen3-TTS-Tokenizer-12Hz)は、単独で高性能な音声コーデックとして利用可能です。
このトークナイザは、入力されたアナログ波形を12.5Hzという非常に低いフレームレートで離散的なトークン列(コード)に圧縮します。一般的な音声コーデックと比較しても、極めて低いビットレートで意味情報と音響情報の両方を保持できるため、ネットワーク帯域幅の節約やストレージ効率の向上に大きく寄与します。また、再構成された音声品質(Reconstruction Quality)においても、従来のニューラルコーデックを上回るスコアを記録しています。
以下は、任意の音声ファイルをトークン列にエンコードし、再び波形に戻す(ラウンドトリップさせる)コード例です。この仕組みを利用することで、例えば「音声をトークン化して送信し、受信側でデコードする」といった低帯域幅での音声通信システムや、音声データをトークン形式でデータベースに効率的に格納するシステムの構築が可能になります。
import soundfile as sf
from qwen_tts import Qwen3TTSTokenizer
# 1. トークナイザのロード
# ここでは圧縮効率と低遅延に優れた12Hzモデルを使用します。
tokenizer = Qwen3TTSTokenizer.from_pretrained(
"Qwen/Qwen3-TTS-Tokenizer-12Hz",
device_map="cuda:0",
)
# 2. 音声ファイルの読み込み
# numpy array形式、またはファイルパスやURLを直接渡すことも可能です。
ref_audio, sr = sf.read('reference_sound.wav')
# 3. エンコード(圧縮)
# 音声波形を離散的なコード(整数の配列)に変換します。
# この時点でデータサイズは劇的に圧縮されており、ネットワーク伝送に適した形式になります。
enc = tokenizer.encode(ref_audio, sr)
# 4. デコード(復元)
# コード列から音声波形を再構成します。
# 12Hzモデルは軽量なConvNetデコーダを使用しているため、処理は高速です。
wavs, sr = tokenizer.decode(enc)
# 5. 結果の保存
sf.write("decode_output.wav", wavs, sr)
おわりに
Qwen3-TTSは、従来のTTSモデルが抱えていた「高品質」と「低遅延」のトレードオフを、革新的なデュアルトラック・アーキテクチャと独自のトークナイザ技術によって解消しました。特に12Hzトークナイザを採用したモデルは、First-packet latency 97msという極めて低いレイテンシを実現しており、LLMと組み合わせたリアルタイム対話システムへの組み込みにおいて強力な選択肢となります。
また、Voice Designで創出したキャラクターをClone機能で運用する柔軟なワークフローは、エンターテインメントやコンテンツ制作の現場においても即戦力となる実用性を備えています。Qwen3-TTSは、単なる読み上げソフトを超え、次世代のAIアプリケーション開発における表現の幅を大きく広げるツールとなります。
More Information
- arXiv:2601.15621, Hangrui Hu et al.,「Qwen3-TTS Technical Report」, https://arxiv.org/abs/2601.15621
関連記事

PySR: シンボリック回帰とは何か?
シンボリック回帰(Symbolic Regression、記号回帰とも呼ばれます)は、データを説明する数式を自動的に見つけ出す機械学習手法です。この手法では、関数の形式を事前に決めることなく、与えられたデータに最も合う数 […]

torchmil入門:PyTorchによる深層マルチインスタンス学習の実践
現代の機械学習では、詳細なラベルを全てのデータに付与することが困難な場面が多く見られます。特に医療画像診断のような分野では、ピクセル単位の精緻なアノテーション(Annotation)には専門家の多大な労力が必要となり、実 […]

promptolution: Pythonによるプロンプト最適化の実践
大規模言語モデル(LLM)を活用する際、その出力性能は入力プロンプト(指示文)の品質に大きく左右されます。この「プロンプトの感度(sensitivity)」は非常に高く、意味的に類似しているように見えるわずかな表現の違い […]