torchmil入門:PyTorchによる深層マルチインスタンス学習の実践
現代の機械学習では、詳細なラベルを全てのデータに付与することが困難な場面が多く見られます。特に医療画像診断のような分野では、ピクセル単位の精緻なアノテーション(Annotation)には専門家の多大な労力が必要となり、実用上の大きな障壁となっています。このような状況で、詳細なアノテーションが利用できない弱教師あり学習の強力な手法として注目を集めているのが、マルチインスタンス学習(Multiple Instance Learning, MIL) です。MILは、個々のデータポイント(インスタンス)ではなく、それらをまとめた集合体(バッグ)にのみラベルが付与されている場合に有効なアプローチです。
深層マルチインスタンス学習の分野では、モデルの開発、評価、比較のための標準化されたツールが不足しており、これが研究の再現性や新規ユーザーの参入障壁となっていました。
この課題に対処するため、PyTorchをベースとしたオープンソースのPythonライブラリ「torchmil」が開発されました。torchmil は、MILモデルの構築、トレーニング、評価のための統一された、モジュール式で拡張可能なフレームワークを提供し、標準化されたデータ形式やベンチマークデータセットとモデルを含んでいます。
今回は、torchmil の主な特徴、機能、およびその活用方法を解説します。
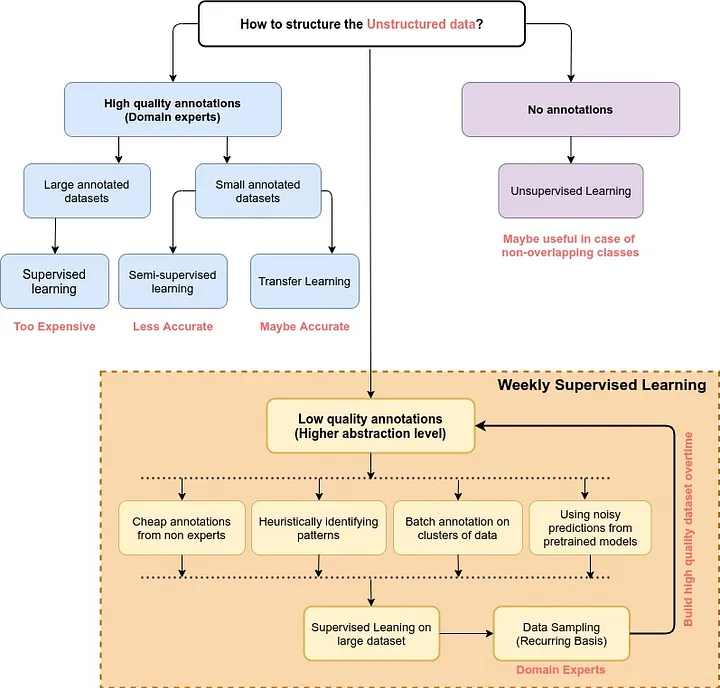
弱教師あり学習とは?
弱教師あり学習(Weakly Supervised Learning)は、従来の教師あり学習とは異なり、より少ない、またはあいまいな形式の教師信号から学習するアプローチです。従来の教師あり学習では、各データポイントに厳密なラベルが要求されますが、現実には詳細なアノテーションの準備は非常に困難でコストがかかります。
この課題は、特に医療画像解析のような専門性の高い分野で顕著です。例えば、ホールスライド画像(Whole Slide Images, WSIs)の場合、がん組織の有無をピクセル単位で正確にアノテーションするには、病理医の膨大な時間と労力が必要です。1枚のWSIが数千の微細なパッチから構成されるため、すべてのパッチにラベルを付与することは非現実的です。また、CTスキャンで脳内出血を検出する際も、各スライスに異常箇所を詳細にマークする作業は同様にコストがかかり、困難を伴います。
弱教師あり学習は、このような状況で真価を発揮します。個々の詳細なラベルではなく、より粗い粒度や集合体(例えば「このWSIにはがん組織がある」といった画像全体のラベル)に対する情報から学習を進めることができるため、アノテーションの負担を大幅に軽減しつつ、実用的なモデル開発を可能にします。深層マルチインスタンス学習(Deep Multiple Instance Learning, MIL)は、この弱教師あり学習の強力なフレームワークとして広く活用されています。
マルチインスタンス学習とは?
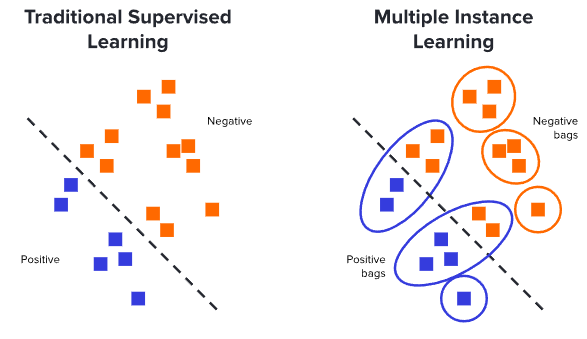
マルチインスタンス学習(Multiple Instance Learning, MIL)は、データ構造に特徴を持つ弱教師あり学習の一種です。MILでは、トレーニングデータは個々の要素ではなく、それらをまとめた「バッグ(Bag)」と呼ばれる集合体として扱われます。このバッグは複数の「インスタンス(Instance)」から構成されており、ラベルが割り当てられるのはこのバッグ単位です。個々のインスタンスのラベルは、トレーニング時には不明であることが前提となりますが、評価目的でテスト時に利用できる場合もあります。
バッグのラベルとインスタンスのラベルには特定の関係性が仮定されます。最も一般的なシナリオは、バッグが陽性(Positive)であるのは、その中に少なくとも1つの陽性インスタンスが含まれる場合です。逆に、バッグが陰性(Negative)であれば、その中の全てのインスタンスも陰性であると推測されます。
MILは、計算病理学(Computational Pathology)、既存薬再開発(Drug Repositioning)、動画のイベント検出(Video Event Detection)など、幅広い分野で応用されています。特に、医療画像解析ではその真価を発揮します。例えば、ホールスライド画像(Whole Slide Images, WSIs)の場合、1枚のWSI全体がバッグと見なされ、それを構成する微細な画像領域(パッチ)が個々のインスタンスとなります。同様に、CTスキャンでは、CTスキャン全体がバッグであり、個々のスライスがインスタンスとして扱われます。これらの例では、WSIやCTスキャン全体のラベルは存在するものの、各パッチやスライスごとの詳細な異常箇所の特定は困難であるため、MILのアプローチが非常に有効です。
MILデータは、各バッグに含まれるインスタンスの数が異なったり、インスタンス間に空間的・位相的な関係が存在したりするなど、複雑な構造を持つことがしばしばです。この複雑さが、モデルの前処理戦略や実装の詳細に大きく影響し、研究の再現性や新規ユーザーにとってのアクセシビリティを阻害する課題となっていました。
torchmilの概要
torchmil は、MILモデルの構築、トレーニング、評価のための統一された、モジュール式で拡張可能なフレームワークを提供します。PyTorchを基盤とし、標準化されたデータ形式、厳選されたベンチマークデータセット、そして多様なモデルの実装を含んでいます。
主要モジュールの機能
torchmilは、以下の主要サブモジュールで構成されています。
torchmil.data: MILデータの表現を標準化し、バッグ構造やバッチ処理に対応します。torchmil.datasets: MIL用データセットを提供します。ProcessedMILDatasetやCAMELYON16、RSNA、PANDAといったベンチマークデータセットも含まれます。torchmil.nn: Deep MILモデル構築に必要なPyTorchモジュール群です。アテンション、グラフニューラルネットワーク(GNN)、Transformer、Smオペレーター、プーリングなどが含まれます。torchmil.models:ABMILやTransMILといった人気のディープMILモデルを実装しており、共通インターフェースでモデルの利用を簡素化します。torchmil.visualize: モデル結果を直感的に理解するための可視化ツールを提供します。CTスキャンやWhole Slide Images(WSI)のパッチ、ヒートマップ描画などが可能です。torchmil.utils: MIL開発プロセスを効率化する汎用ユーティリティです。トレーニングループを簡素化するTrainerクラス、学習スケジューラー、グラフ操作関数 などが含まれます。
torchmilにおけるデータの表現方法
torchmilは、マルチインスタンス学習の複雑なデータ構造を効率的に扱うために、標準化されたデータ表現を導入しています。主にtorchmil.dataモジュールで提供される機能の中核をなす部分です。
バッグの表現
torchmilでは、MILにおける各バッグ(Bag)は、PyTorch Geometricのデータ表現に着想を得たTensorDictオブジェクトとして表現されます。TensorDictは、バッグに関するインスタンス特徴やラベルなど、多様な情報を柔軟に格納できる辞書のような構造であり、MILデータの一元管理を可能にします。
バッグが持つ主なキーには、以下のようなものがあります:
- 必須のキー:
bag['X']: バッグ内のインスタンス特徴を表すテンソル(Tensor)です。通常、その形状は(bag_size, feature_dim)(バッグのサイズ、特徴の次元)となります。bag['Y']: バッグ全体のラベルを表すテンソルです。多くの場合スカラーですが、多クラス分類問題では異なる形状を持つこともあります。
- 一般的な追加キー:
bag['y_inst']: バッグ内のインスタンスごとのラベルを表すテンソルです。純粋なMIL設定ではトレーニング時にはこの情報は不明であり、主に評価目的で利用されることが多いです。bag['adj']: インスタンス間の隣接行列(Adjacency Matrix)を表すテンソルです。(bag_size, bag_size)の形状を持ち、インスタンス間の関係性(例えば、空間的な近接度など)を表現します。スパーステンソル(Sparse Tensor)にも対応しています。bag['coords']: インスタンスの座標(Coordinates)を表すテンソルです。(bag_size, coords_dim)の形状で、インスタンスの絶対的な空間位置を保持します。
このようなTensorDictは、インスタンス特徴やラベル、さらに補助的な情報である隣接行列や座標といった要素を辞書形式で一元的に管理できるため、非常に直感的で扱いやすいデータ構造です。
バッチ処理の工夫
深層学習モデルのトレーニングには効率的なバッチ処理が不可欠ですが、MILでは各バッグに含まれるインスタンスの数が異なるため、これが課題となります。torchmilでは、この問題に対処するために、バッグ内のテンソルをバッチ内で最も大きいバッグのサイズに合わせてパディング(Padding)します。
さらに、パディングされた要素が実際のインスタンスと区別されるように、マスクテンソル(Mask Tensor)を使用します。このマスクは、モデルがパディング要素を無視するように挙動を調整する際に利用されます(例えば、アテンションメカニズムなど)。
torchmil.data.collate_fn関数は、異なるサイズのバッグのリストをバッチにまとめる際に、このパディングとマスクテンソルの生成を自動的に行います。現時点ではPyTorchのNested Tensor APIがまだプロトタイプ段階であるため、torchmilは現在のところこのパディングアプローチを採用しています。
表現の種類:シーケンシャルと空間表現
torchmilでは、バッグのインスタンスは大きく2つの方法で表現できます:
- シーケンシャル表現(Sequential Representation):
bag['X']が形状(bag_size, dim)のテンソルである、最も一般的な形式です。インスタンスがリストとして並べられたようなイメージです。空間的な構造を持つデータの場合、この表現はbag['adj'](隣接行列)やbag['coords'](座標)と組み合わせて使用されることがあります。 - 空間表現(Spatial Representation):
bag['X']が空間次元を含むテンソルとして表現される形式です。例えば、Whole Slide Images (WSI)のような医療画像データでは、bag['X']が(height, width, feature_dim)のような形状を持つことで、パッチの空間配置を直接的に表現できます。
torchmilは、torchmil.data.seq_to_spatial関数とtorchmil.data.spatial_to_seq関数を提供しており、これらの表現形式を必要に応じて相互に変換することが可能です。これにより、様々なDeep MILモデルの入力要件に柔軟に対応できます。
torchmilに含まれるモジュール
torchmil.nnモジュールは、深層マルチインスタンス学習(Deep MIL)モデル構築のためのPyTorchモジュール集です。MILモデルで頻繁に利用される多様なアーキテクチャやメカニズムをカバーしています。
- アテンションモジュール (Attention Modules): インスタンス特徴の重要度を学習し、バッグ表現を集約します。例として、AttentionPool、SmAttentionPool、MultiheadSelfAttention などがあります。
- グラフニューラルネットワーク (GNN) モジュール: インスタンス間の関係性をモデル化します。GCNConv やDenseMinCutPool などのグラフ畳み込み層やプーリング層が利用可能です。
- Transformerモジュール: 自己アテンションでインスタンス間の長距離依存関係を捉えます。TransformerEncoder やSmTransformerEncoder、NystromTransformerEncoder など多様な実装があります。
- Smオペレーター: グラフ上のノード特徴の滑らかさ(Smoothness)を促進するために提案された演算子です。ApproxSmやExactSmモードがあり、特に構造化データに効果的です。
- プーリングモジュール: インスタンス特徴を集約し、バッグレベルの表現を生成する基本メカニズムです。
MaxPool(最大プーリング) とMeanPool(平均プーリング) が提供されます。
torchmilに含まれるモデル
torchmil.modelsモジュールは、深層マルチインスタンス学習(Deep MIL)の分野で広く知られている様々なモデルを提供しています。これらのモデルはすべてMILModelベースクラスを継承しており、統一されたインターフェースを通じて、モデルの構築、トレーニング、評価を簡素化します。以下に、主要なモデルとその特徴、メリットをまとめます。
| 手法名 | 主要技術・特徴 | アーキテクチャの特徴 | 損失関数・学習戦略 | 空間情報の活用 |
|---|---|---|---|---|
| ABMIL | Attention-base Pooling | 特徴抽出器 + AttentionPool + 線形分類器 | 標準的なバッグラベル予測 | なし |
| CAMIL | Context-aware MIL | NystromTransformerLayer (グローバル) + CAMILSelfAttention (ローカル) + CAMILAttentionPool | グローバル・ローカル情報融合 | 隣接行列使用 |
| CLAM | Clustering Constrained Attention | ABMILと同一のフォワードパス | インスタンスレベル正則化 + 疑似ラベル生成 + クラスタリング分類器 | なし |
| DFTDMIL | Double Feature Distillation | 疑似バッグ分割 + Tier1&2の二層構造 | Tier1: アテンション予測, Tier2: Grad-CAM + 蒸留損失 | なし |
| DSMIL | Double Stream Learning | ストリーム1: インスタンス分類器, ストリーム2: クエリ-キーマッチング | バッグ損失 + クリティカルインスタンス損失 | なし |
| GTP | Graph Transformer | GCN + min-cut pooling + Transformerエンコーダ + クラストークン | BCE損失 + MinCut損失 + 直交性損失 | グラフ構造 |
| ProbSmoothABMIL | Probabilistic Smooth Attention | ABMILベース + 確率的プーリング (ガウス分布サンプリング) | 標準損失 + KLダイバージェンス正則化 | なし |
| SmABMIL | Smooth Attention | ABMILベース + Smオペレーター組み込みプーリング | 標準的なバッグラベル予測 | グラフベースのスムーズ化 |
| SmTransformerABMIL | Smooth Transformer Attention | SmTransformerEncoder + SmAttentionPool | 標準的なバッグラベル予測 | グラフベースのスムーズ化 |
| TransformerABMIL | Transformer-base Attention | TransformerEncoder + AttentionPool | 標準的なバッグラベル予測 | なし |
| TransformerProbSmoothABMIL | Transformer + Probabilistic Smooth | TransformerEncoder + 確率的アテンションプーリング | 標準損失 + KLダイバージェンス正則化 | なし |
| TransMIL | Correlation MIL Transformer | シーケンススクエアリング + TPT (Nyströmformer + PPEG) + クラストークン | 標準的なバッグラベル予測 | 位置エンコーディング |
| SETMIL | Space Encoding Transformer | PMF (多スケール融合) + SET (空間エンコーディングTransformer) + iRPE | 標準的なバッグラベル予測 | 画像相対位置エンコーディング |
| IIBMIL | Integrated Instance Bag Learning | TransformerEncoder + Transformerデコーダ | バッグレベル + インスタンスレベル二重学習 + プロトタイプ更新 | コンテキスト情報活用 |
torchmilの使い方
torchmilは、PyTorchをベースとした深層多インスタンス学習(MIL)のためのオープンソースPythonライブラリです。MILは、きめ細かいアノテーションが利用できない場合に特に有用な弱教師あり学習の強力なフレームワークであり、torchmilはMILモデルの開発、評価、比較のための統一されたモジュール式で拡張可能なフレームワークを提供することを目指しています。
セットアップ
torchmilのインストールは、以下の通りパッケージインストーラー(pip)を使用します。これのみで、torchmilのすべての機能を利用できるようになります。
$ pip install torchmil
コード例
まずは、torchmilの主要なコンポーネントをインポートします。
CAMELYON16MILDataset: CAMELYON16データセットを扱うためのクラスです。ABMIL: Attention-based Multiple Instance Learning (ABMIL) モデルのクラスです。Trainer: モデルの訓練プロセスを管理する汎用トレーナークラスです。collate_fn: 異なるサイズの「バッグ」を持つMILデータセットにおいて、バッチ処理を適切に処理するためのユーティリティ関数です。DataLoader: PyTorch標準のデータローダーです。
from torchmil.datasets import CAMELYON16MILDataset from torchmil.models import ABMIL from torchmil.utils import Trainer from torchmil.data import collate_fn from torch.utils.data import DataLoader
次に、CAMELYON16データセットを読み込み、データローダーを設定します。
CAMELYON16MILDataset: CAMELYON16は、リンパ節切片のWhole Slide Images (WSIs) における乳がん転移検出のためのベンチマークデータセットです。torchmilでは、WSIが「バッグ」、パッチが「インスタンス」として扱われます。root='./data': データセットが保存されているルートディレクトリを指定します。features='UNI': 使用する特徴の種類を指定します。例えば、「UNI」や「resnet50_bt」などが選択できます。dataloader = DataLoader(...): データセットからミニバッチを効率的にロードするために使用されます。batch_size=4: 各ミニバッチに含まれる「バッグ」の数です。MILでは各バッグのサイズが異なる可能性があるため、この値は慎重に選択します。shuffle=True: トレーニング中にデータをシャッフルします。collate_fn=collate_fn: マルチインスタンス学習 (MIL) のデータ表現において非常に重要です。MILでは各バッグのインスタンス数が異なるため、通常のPyTorchDataLoaderでは直接バッチ化できません。torchmil.data.collate_fn関数は、バッチ内の最大のバッグサイズに合わせてテンソルをパディングし、実際のインスタンスとパディングを区別するためのマスクテンソルを生成します。これにより、モデルはパディング要素を無視して動作を調整できます。PyTorchのnestedテンソルAPIはまだプロトタイプ段階にあるため、torchmilは現在パディングアプローチに依存しています。
# Load the Camelyon16 dataset dataset = CAMELYON16MILDataset(root='./data', features='UNI') dataloader = DataLoader(dataset, batch_size=4, shuffle=True, collate_fn=collate_fn)
次は、モデルとオプティマイザの初期化です。
model = ABMIL(...): ABMIL (Attention-based Multiple Instance Learning) モデルをインスタンス化しています。このモデルは、アテンションベースのプーリングメカニズムを使用して、インスタンスの特徴をバッグ表現に集約し、そのバッグ表現を線形分類器に通してバッグラベルを予測します。in_shape=(2048,): 特徴抽出器(デフォルトではtorch.nn.Identity())が期待する入力データの形状(バッチ次元を除く)です。CAMELYON16データセットの「UNI」特徴やRSNAデータセットの「resnet50」特徴の次元が2048である例が示されています。criterion=torch.nn.BCEWithLogitsLoss(): モデルが使用する損失関数を指定しています。デフォルトでは、二値分類のためのバイナリ交差エントロピー損失が使用されます。
optimizer = torch.optim.Adam(...): Adamオプティマイザを使用します。
# Instantiate the ABMIL model and optimizer model = ABMIL(in_shape=(2048,), criterion=torch.nn.BCEWithLogitsLoss()) # each model has its own criterion optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
Trainerクラスをインスタンス化します。
Trainer:torchmil.utilsに含まれる汎用トレーナークラスであり、MILモデルのトレーニングプロセスを簡素化します。ロギング、評価メトリクスの計算、学習率スケジューラ、早期停止などの機能を提供します。device='cuda': モデルがGPU(CUDA)上で訓練されることを指定しています。GPUが利用できない場合は'cpu'を使用できます。
# Instantiate the Trainer trainer = Trainer(model, optimizer, device='cuda')
Trainerオブジェクトのtrainメソッドを呼び出して、モデルの訓練を開始します。
dataloader: 上で定義したデータローダーからデータを供給します。epochs=10: ここでは、訓練エポック数を10とします。訓練中、Trainerは進捗バーや指定されたメトリクス(例:損失や精度)の進化を表示します。
# Train the model trainer.train(dataloader, epochs=10)
最後に、訓練済みのモデルのパラメータ(状態辞書)をmodel.pthというファイルに保存します。これにより、後で訓練済みモデルをロードして再利用したり、推論を行ったりすることができます。
# Save the model torch.save(model.state_dict(), 'model.pth')
おわりに
今回は、深層マルチインスタンス学習(Deep MIL)のPyTorchベースライブラリである「torchmil」について、その主要な特徴と機能を紹介しました。torchmilは、これまで標準化されたツールが不足していたDeep MILの分野において、モデル開発、評価、比較を統一的かつモジュール式で拡張可能なフレームワークとして提供することで、研究開発を加速し、新規ユーザーの参入障壁を大幅に低減することを目指しています。
特に、ホールスライド画像(WSI)におけるがん検出やCTスキャンにおける脳内出血検出といった医療画像解析のような、詳細なアノテーションが困難な複雑なMILタスクにおいて、torchmilは強力で効率的なソリューションとなることを実証しています。標準化されたデータ表現、豊富なベンチマークデータセット、そして様々なモデルの実装は、実務者がこれらの課題に容易に取り組めるよう設計されています。
今後もtorchmilが、Deep MIL分野の発展を支える共通プラットフォームとして、さらなる進化を促進することを期待しています。
More Information
- arXiv:2509.08129, Francisco M. Castro-Macías, Francisco J. Sáez-Maldonado, Pablo Morales-Álvarez, Rafael Molina, 「torchmil: A PyTorch-based library for deep Multiple Instance Learning」, https://arxiv.org/abs/2509.08129
関連記事

機械学習における敵対的攻撃とは何か?
AI、特に深層学習モデルが社会に急速に浸透し、画像認識から自動運転まで、その能力は目覚ましい進化を遂げています。しかし、その成果の裏で、モデルが抱える深刻な脆弱性については、まだ広く知られていません。実は、現在のAIモデ […]

LiteASR: 低ランク近似による効率的な自動音声認識の実現
近年、OpenAIのWhisperに代表される大規模な自動音声認識(ASR)モデルが目覚ましい発展を遂げていますが、その計算コストの高さが実用上の課題となっています。特に、リアルタイム処理やリソース制約のある環境での利用 […]

ボルツマン分類器: 熱統計力学に着想を得た超高速クラス分類器
機械学習の世界では、日々新しいアルゴリズムや興味深い論文が発表されています。そんな中、最近「Boltzmann Classifier: A Thermodynamic-Inspired Approach to Super […]