iLTM: 表形式データ向けの大規模基盤モデル

表形式データのモデリングにおいて、長らく実務のデファクトスタンダードとして君臨してきたのは勾配ブースティング決定木(GBDT)でした。画像や自然言語の分野で深層学習が席巻する中、表形式データだけは「GBDTが最適解」という状況が続いています。
しかし、その常識を変える可能性を秘めた新しい「基盤モデル」が登場しました。スタンフォード大学の研究チームらが提案した「iLTM (Integrated Large Tabular Model)」です。iLTMは、GBDTの強みとニューラルネットワークの柔軟性を統合し、1,800以上のデータセットによる大規模な事前学習を経て、従来のGBDTや深層学習モデルを上回る性能を実証しました。
この記事では、このiLTMのアーキテクチャの特徴から、実務における技術的な利点、そしてPythonを用いた実装方法までを詳しく紹介します。
iLTMの概要とアーキテクチャ
iLTM (Integrated Large Tabular Model) は、その名の通り、異なるアプローチを1つのアーキテクチャに「統合」したモデルです。具体的には、表形式データで圧倒的な強さを誇る「決定木(GBDT)の帰納バイアス」と、深層学習の「柔軟な表現力」を融合させています。
このモデルは、1,800以上の多様なデータセットで事前学習されており、未知のタスクに対してもファインチューニングなし、あるいは最小限の調整で高い性能を発揮します。アーキテクチャは主に以下の3つのコンポーネントで構成されています。
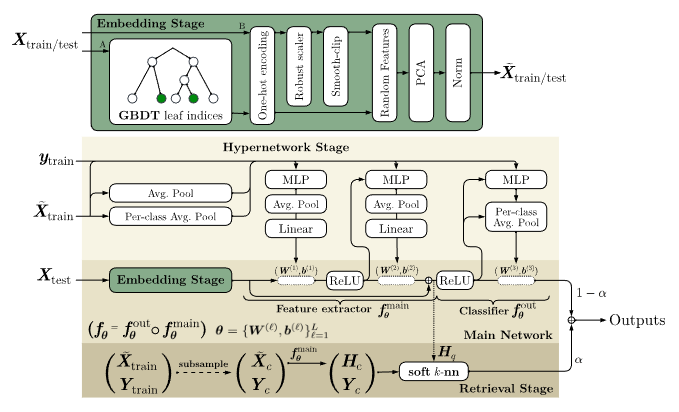
GBDTエンベディングと前処理
iLTMの入り口では、生の表形式データに対して、XGBoostやCatBoostといったGBDTモデルを適用します。ここで重要なのは、GBDTを最終的な予測器として使うのではなく、「特徴量抽出器」として利用する点です。
具体的には、決定木の葉(Leaf)のインデックス情報を利用してデータをエンベディング(ベクトル化)します。これにより、以下のメリットが生まれます。
- 面倒な前処理の自動化: カテゴリ変数のエンコーディング、欠損値の補完、外れ値の処理といった、通常エンジニアが手動で行う作業をGBDTが内部で処理します。
- 不連続なパターンの学習: ニューラルネットワークが苦手とする、段階的(非連続)な決定境界を決定木が捉え、その情報を後続のネットワークに渡します。
また、GBDTを使用しない場合でも、ロバストなスケーリングとエンコーディングを行う前処理パイプラインが用意されており、データはニューラルネットワークが扱いやすい形式(固定長の表現)に変換されます。
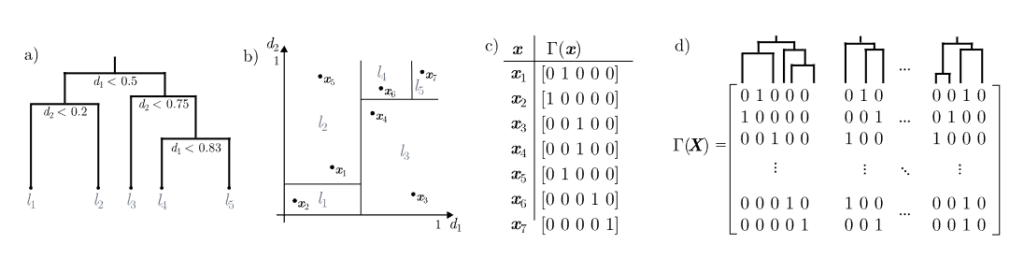
メタ学習されたハイパーネットワーク
iLTMの「頭脳」にあたるのが、メタ学習(Meta-Learning)されたハイパーネットワークです。
通常、ニューラルネットワークを学習させる際は、タスクごとにランダムな初期値から重みパラメータを更新していきます。しかし、iLTMのハイパーネットワークは、入力されたデータの特性(次元数に依存しない固定長表現)を受け取り、そのタスクに最適なメインネットワーク(MLP)の重みパラメータそのものを生成します。
1,800以上の分類タスクで「重みの作り方」を学習しているため、新しいデータセットが与えられた瞬間、即座に適切なニューラルネットワークを構築できます。これが、iLTMが高い汎化性能と学習効率を実現している理由です。
検索拡張 (Retrieval)
推論の精度をさらに高めるために、iLTMは検索拡張(Retrieval-Augmented Classification)の仕組みを導入できます。
これは、LLM(大規模言語モデル)におけるRAG(検索拡張生成)の表形式データ版と考えるとイメージしやすいです。推論時に、学習データの中から「似ている事例」を検索し、そのラベル情報を予測の手がかりとして利用します。このソフトなk近傍法(k-NN)のようなメカニズムにより、特にデータ数が少ない場合や複雑な決定境界を持つタスクにおいて、予測性能が向上します。
技術的な利点とパフォーマンス
既存の強力なモデルと比較して、iLTMが提供する主な技術的メリットは以下の3点に集約されます。
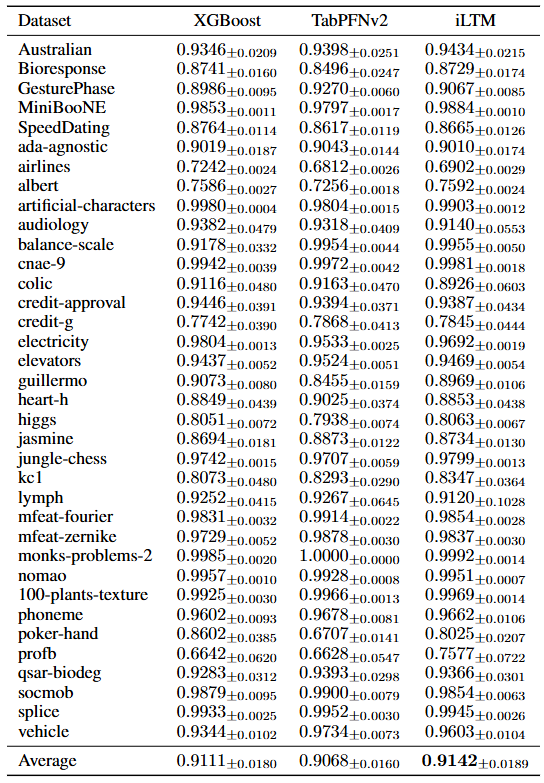
- 最高レベルの予測性能: 厳格なベンチマークとして知られる「TabZilla Hard」において、iLTMはチューニング済みのXGBoostやCatBoost、さらに最新の深層学習モデルであるTabPFNv2を抑え、平均AUCランクでトップの成績を記録しました。特に、従来の手法が苦戦しやすい高次元データセット(数千〜数万の特徴量を持つ生物医学データなど)においても、XGBoostを上回るAUCスコアを達成しており、そのロバスト性が証明されています。
- タスクを跨いだ転移学習: iLTMのユニークな点は、分類タスクで事前学習された「知識」を回帰タスクにも応用できることです。メタ学習によって獲得された特徴表現は汎用性が高く、わずかなファインチューニングを実施するだけで、回帰タスクにおいても強力なベースラインモデルと同等、あるいはそれ以上の精度を発揮します。これは、データ形式が異なってもモデルがデータの構造を深く理解していることを示唆しています。
- チューニングコストの大幅な削減: 実務でGBDTを使用する場合、タスクごとに広範なハイパーパラメータ探索(グリッドサーチなど)が不可欠であり、これには膨大な計算コストと時間がかかります。一方でiLTMは、メタ学習済みのハイパーネットワークが「良い初期重み」を即座に生成するため、ゼロから学習する場合や既存モデルと比較して、タスクごとの調整コストを劇的に削減可能です。
実装と利用方法
iLTMは、実務での利用を想定してPythonパッケージとして設計されています。scikit-learn に準拠したインターフェースを採用しているため、既存の機械学習パイプラインへの統合も非常にスムーズです。
インストールとセットアップ
インストールはpipコマンド一つで完了します。Linux、macOS、Windowsに対応していますが、計算効率の観点からGPUの利用が強く推奨されています。
$ pip install iltm基本的なコード例
以下は、iLTMを使用して回帰タスク(カリフォルニアの住宅価格予測)を行う基本的な実装例です。iLTMRegressor(分類の場合はiLTMClassifier)を初期化し、.fit()で学習、.predict()で推論を行うという、多くのエンジニアにとって馴染み深いフローで実行できます。
なお、初回実行時には、Hugging Face Hubから事前学習済みのモデルチェックポイントが自動的にダウンロードされ、ローカル(例: ~/.cache/iltm)にキャッシュされます。
import pandas as pd
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
from iltm import iLTMRegressor
# 1. データの準備 (scikit-learnのデータセットを使用)
# as_frame=True にすることで、pandas DataFrame形式で取得できます
print("Loading California Housing dataset...")
housing = fetch_california_housing(as_frame=True)
X = housing.data
y = housing.target
print(f"Dataset shape: {X.shape}")
print(f"Features: {X.columns.tolist()}")
# データを学習用とテスト用に分割
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 2. モデルの初期化
# checkpoint: 回帰タスク向けに強力な "cbrconcat" (CatBoost embedding + 原特徴量結合) を使用
# device: GPUがある場合は "cuda:0"、なければ "cpu"
reg = iLTMRegressor(
n_ensemble=8, # デモ用に少し減らしています (デフォルトは16)
finetuning_max_steps=2000, # ファインチューニングのステップ数
checkpoint="cbrconcat",
device="cuda:0" # 環境に合わせて変更してください
)
# 3. 学習
# eval_set を渡すことで、学習中に検証データでの性能を確認できます
print("Training started...")
reg.fit(
X_train,
y_train,
eval_set=(X_test, y_test),
fit_max_time=120.0 # 2分以内で学習を打ち切る設定 (必要に応じて調整)
)
print("Training finished.")
# 4. 推論
y_pred = reg.predict(X_test)
# 5. 評価
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("-" * 30)
print(f"Mean Squared Error (MSE): {mse:.4f}")
print(f"R2 Score: {r2:.4f}")
print("-" * 30)
# 参考: 特徴量の重要度を確認したい場合 (Permutation Importance)
# iLTM は feature_importance メソッドを持っています
print("Calculating feature importance...")
importance_df = reg.feature_importance(X_test, y_test, n_repeats=3)
print(importance_df.head(5))
ハイパーパラメータの調整と制御
上記のコード例でも使用しているパラメータについて、いくつかの重要なポイントを補足します。
- モデルチェックポイント (
checkpoint): デフォルトのxgbrconcat(XGBoost埋め込み)のほか、コード例にあるcbrconcat(CatBoost埋め込み)など、タスクの性質に応じて様々な構成済みモデルを選択可能です。 - 学習時間の制御 (
fit_max_time): 実務では「学習にかけられる時間」に制約があることが一般的です。iLTMではfit_max_time引数を指定することで、指定時間を超えた場合にその時点までのアンサンブル結果を返す機能があり、柔軟な運用が可能です。 - 探索空間の提供: iLTMはデフォルト設定でも高い性能を発揮しますが、さらなる精度向上のために
iltm.get_hyperparameter_search_space()を通じて推奨される探索空間を提供しています。これにより、Optunaなどの外部ライブラリと組み合わせたチューニングも容易に実施できます。
おわりに
iLTMは、長らく定石であったGBDTの実用性と、ニューラルネットワークの柔軟性を兼ね備えた、表形式データのための強力な基盤モデルです。
1,800以上のデータセットで磨かれたそのロバスト性と、事前学習による高い初期性能は、ハイパーパラメータ探索に費やす時間を大幅に削減し、実務におけるモデル構築を強力に支援します。
「とりあえずXGBoost」という既存のパイプラインに対する強力な補完、あるいは次世代の代替手段として、iLTMは十分に検証に値する技術です。ぜひ一度、お手元のデータでそのポテンシャルを体感してみてください。
More information
- arXiv:2511.15941, David Bonet et al., 「iLTM: Integrated Large Tabular Model」, https://arxiv.org/abs/2511.15941
関連記事

Lightlyで実践 - 自己教師あり学習入門
近年、機械学習プロジェクトで扱うデータ量は増大し続けています。しかし、その膨大なデータすべてに手作業でアノテーション(教師ラベル付け)を行うのは、コストと時間の面で大きな課題です。この「アノテーションの壁」を乗り越える技 […]

TabNet: 表形式データ向け深層学習モデル
ディープラーニングは画像やテキストなどの分野で大きな成功を収めていますが、表形式データにおいては未だに決定木をベースにしたブースティング手法が主流です。しかし、表形式データは実世界において最も一般的なデータであり、ディー […]

OpenVINOによる深層学習モデルのパフォーマンス改善
機械学習モデルの社会実装が加速する現代において、その推論速度は、アプリケーションの応答性、ひいてはユーザー体験を左右する重要な要素となっています。リアルタイム性が求められるエッジAIの現場から、大量データを処理するクラウ […]