LLM×シンボリック回帰: 科学的発見を加速する次世代アプローチ
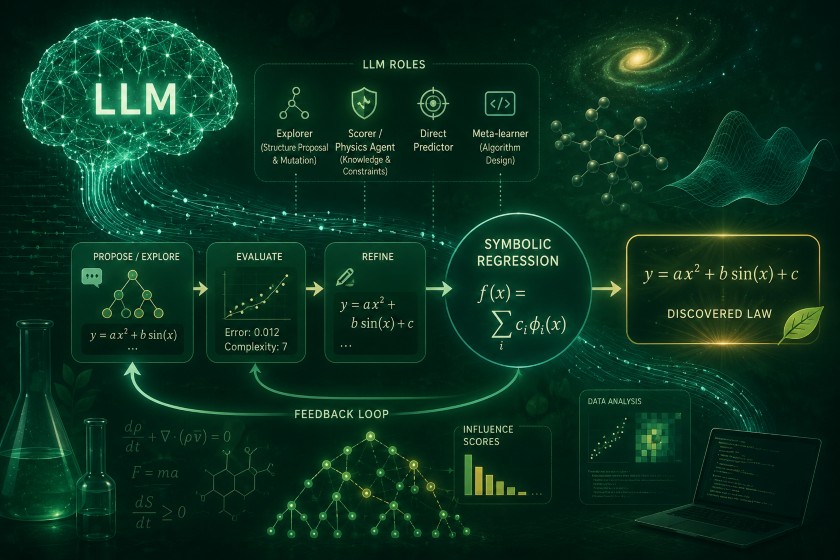
観測データから物理法則や数学的関係式を導き出すシンボリック回帰(SR: Symbolic Regression)をご存知でしょうか?従来の手法では、探索空間の組み合わせ爆発や、事前知識をシステムに組み込む難しさが長年の課題でした。
しかし近年、大規模言語モデル(LLM)を統合することで、この壁を突破する様々な取り組みが進展しています。LLMの強力な文脈内学習(ICL: In-Context Learning)を活用してフィードバックから自己修正を図ったり、モデルが持つ世界知識(Parametric Knowledge)を動員して物理的に妥当な数式へと探索空間を絞り込んだりすることが可能になりました。
この記事では、LLMをSRに活用するアプローチを以下の4つの主要アーキテクチャに分類して解説します。
- 探索演算子: 数式候補の生成や変異を担当
- スコアラー: 物理的整合性や解釈性を評価
- 直接予測器: データから一発で数式を推論
- ハイブリッドシステム: 双レベル最適化などで外部ツールと協調
それぞれの役割や処理ループの違いを紐解きながら、科学的発見を加速する次世代の技術を解説します。
1. アーキテクチャの詳細と物理制約の導入
シンボリック回帰にLLMを組み込む際、どのように数式を生成し、物理的な正しさを担保するのでしょうか。ここでは、その具体的なアーキテクチャと制約の仕組みについて解説します。
連続パラメータ最適化と双レベル最適化
LLMはもともとテキストやトークンの生成モデルです。そのため、数式内の係数として「1.9897」のような浮動小数点数を直接生成させようとすると、高確率で数値的なハルシネーション(でっち上げ)を引き起こします。この微小な係数の狂いは、数式の物理的妥当性を瞬時に失わせる原因になります。
この課題を回避するために採用されているのが「双レベル最適化(Bilevel Optimization)」というアプローチです。
- 上層(LLM): 係数を含まない数式の構造(スケルトン)のみを提案する。
- 下層(外部シミュレータ): SciPyやPyTorchベースの最適化ソルバーが、勾配法を用いて係数を精密に調整する。
このように役割を分担することで、LLMの弱点を補いつつ効率的な数式探索を実施しています。
Physics-Informed Agentによる制約の実装
単なるデータへの当てはめ(フィッティング)を防ぎ、物理法則に則った数式を発見するために、LLMを「物理制約エージェント(Physics-Informed Agent)」として活用する手法(EO-SRなど)が存在します。
例えば、材料力学におけるDruckerの安定条件を満たすには、ひずみエネルギー関数のHessian行列が半正定値(凸性を持つこと)である必要があります。LLMはこの専門的な条件を理解し、実行可能な数学的制約コード(ペナルティ関数)としてゼロショットで自動合成します。これにより、物理的に破綻する危険な数式を探索空間から効果的に除外できます。
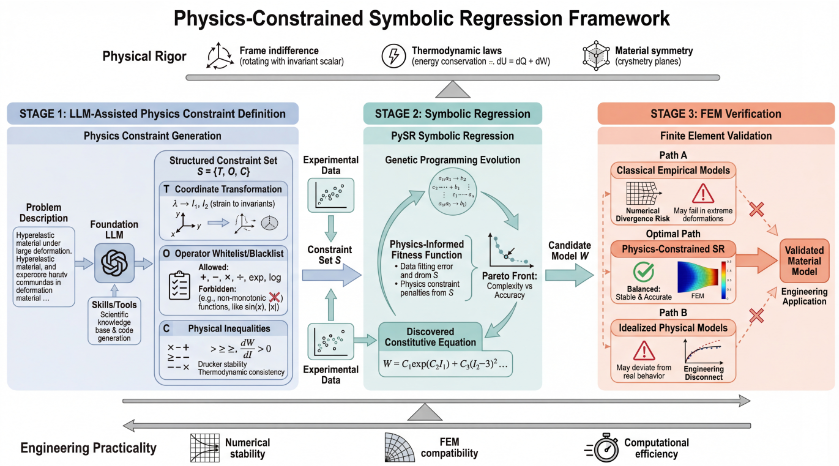
シミュレーション連携とハイブリッド構成則
物理制約の導入は、有限要素法(FEM: Finite Element Method)シミュレーションの安定性に直結します。従来のOgdenモデルなどの経験式は、引張データのみでパラメータを調整すると、強い圧縮条件下で特定の剛性項が指数関数的に爆発し、ヤコビ行列の悪条件化を引き起こしてシミュレーションを破綻させる弱点がありました。
対して、物理制約を取り入れたEO-SRが発見した新しい構成則は、非常に理にかなった構造をしています。
- 線形項: 従来のMooney-Rivlinモデルに由来し、小~中ひずみ領域の弾性を表現する。
- 有理数型のロック項: 分子鎖の物理的な伸び切り限界(有限伸張性)を表現する。
このハイブリッド構造により、大ひずみ領域でも過剰な剛性爆発を防ぐことができ、FEMシミュレーション上で極めて安定した計算が可能になります。
LLM-Feynmanによる多目的最適化
さらに、数式の評価基準を高度化し、発見プロセスを洗練させる取り組みも進んでいます。LLM-Feynmanというフレームワークでは、以下の損失関数 \(L\) を用いて多目的最適化に取り組みます。
$$L = \alpha N(E) + \beta N(C) + \gamma S$$
ここで、$E$ は予測誤差、\(C\) は数式の複雑さを表し、\(S\) はLLMがドメイン知識に基づいて自ら付与する「解釈性スコア」を示します。このスコアを取り入れたパレート・フロント最適化により、単に精度が高く簡潔であるだけでなく、科学的に意味のある数式が優先的に選ばれるようになります。
また、このプロセスにはモンテカルロ木探索(MCTS: Monte Carlo Tree Search)が組み込まれています。LLMが生成した「なぜこの数式でターゲットを予測できるのか」という物理的・化学的な仮説をMCTSの探索木上で評価し、系統的に洗練させていくことで、データと理論が合致した説得力のある説明の構築を実現しています。
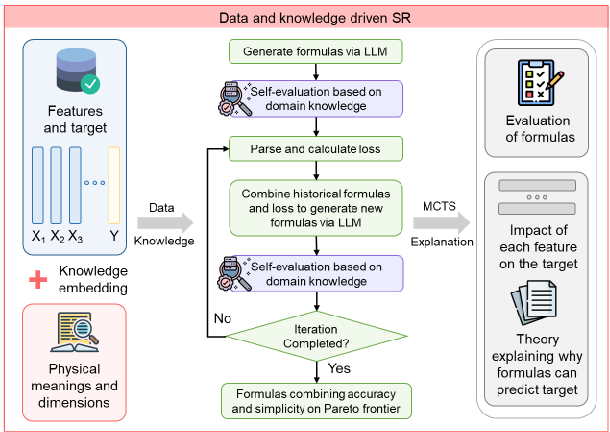
2. コンテキスト学習とプロンプトエンジニアリングの実践
LLMを活用したシンボリック回帰において、単に数値データと指示を渡すだけでは最適な数式を導き出すことは困難です。LLMの文脈内学習(ICL: In-Context Learning)の能力を最大限に引き出すためには、プロンプトエンジニアリングの工夫が不可欠となります。ここでは、様々なタスクで数式探索を効率化し、精度を高めるための実践的なアプローチを解説します。
Scratchpad(思考領域)の導入効果
LLMにいきなり最終的な数式を出力させるのではなく、プロンプト内に「Scratchpad(思考領域)」を設け、段階的な推論プロセスを自然言語で記述させる手法が効果を上げています。例えば、材料表面へのガスの吸着量を予測するLangmuirモデルの発見タスクでは、Scratchpadを活用することで「独立変数が増加すると従属変数が減少するため、反比例の関係がある」といったデータパターンの観察がLLM自身によって明確に言語化されます。このような事前分析のプロセスを経ることで、出力される数式の構造が定性的に改善されることが実証されています。
ドメイン固有の制約指示
科学的な観測データには、背景となる物理的・化学的な前提が存在します。純粋なデータへの当てはめのみに依存すると、データに適合していても理論的に破綻している数式(例:圧力がゼロのときに吸着量がマイナスになるなど)が生成される危険性があります。これを防ぐため、プロンプトを通じて自然言語でドメイン固有の制約を直接指示する取り組みが実施されています。 吸着等温式の発見においては、具体的に以下のような制約を文章としてプロンプトに組み込みます。
- 原点を通る(独立変数が0のとき、従属変数も0に近づく)
- 単調非減少である(独立変数が増加するにつれて、従属変数も減少しない)
これらの制約を指示することで、理論に反する無効な数式が探索空間から効果的に排除され、精度と複雑さのバランスを示すパレート・フロントの妥当性が大幅に向上します。
大規模データへの対応
流体力学におけるNikuradseデータセットのように観測点が多い大規模データに対処する場合、全データをそのままプロンプトに含めるとLLMのコンテキスト長の制限を超過し、APIコストも膨大になってしまいます。 この課題を回避するため、「データサンプリングと外部最適化」を連携させる手法が導入されています。具体的には、LLMにはデータ全体の10%〜20%程度のみをサンプリングしてプロンプトに提示し、データ構造の把握と数式スケルトンの提案を担当させます。その後、提案された数式の係数調整や誤差(MAEなど)の評価は、外部の最適化ソルバーを用いて元の全データに対して実施します。この役割分担により、コンテキスト制限や計算コストの問題を回避しつつ、データ全体の傾向を正確に捉えた数式探索を進めることが可能になります。
3. 探索アルゴリズムの高度化とフィードバック機構
LLMを活用した数式探索において、単に予測誤差の大小をフィードバックするだけでは効率的な最適化は望めません。本章では、より細粒度で多角的なフィードバックを探索ループに組み込む最新のアルゴリズムを解説します。
IGSRの Influence Score と間引きサイクル
従来のシンボリック回帰では、モデル全体の平均二乗誤差(MSE: Mean Squared Error)などを評価指標としていました。しかしこれでは、数式を構成する「どの項」が実際に精度へ貢献しているのかが分かりません。 この課題に対処するため、IGSR(Influence-Guided Symbolic Regression)という手法では、個別の基底関数(項)を削除した際の誤差の増分を「Influence Score(\(\Delta_j\))」として算出します。この細粒度なスコアを利用することで、本当に汎化性能へ寄与している項だけを正確に特定できる数学的な利点があります。
さらにIGSRは、モンテカルロ木探索(MCTS: Monte Carlo Tree Search)の中で「Propose-and-Prune(提案と間引き)」サイクルを採用しています。ここでは、LLMが科学的コンテキストに基づいて確率的に様々な項を提案(Propose)し、その後インフルエンス・スコアの低い項を決定論的に間引きます(Prune)。これにより、LLMの柔軟な創造性と、データに基づく厳格な統計的選択を見事に両立させています。
プログラム生成によるコンテキスト拡張
また、数値的なフィードバックから脱却するアプローチも登場しています。PROAUG(Programmatic Context Augmentation)と呼ばれるフレームワークでは、LLM自身にデータ分析コードを自動生成させます。生成されたコードを実行して変数間の統計的な相関を抽出し、その結果を探索プロンプトのコンテキストに直接組み込みます。これは、人間が事前のデータ分析を通じて仮説を立てるプロセスを、LLMに模倣させていると言えます。

高度な探索が導いた科学的発見の事例
これらの探索アルゴリズムの高度化は、実際の科学的発見において強力な成果を上げています。
- PROAUGによるケプラーの第3法則の導出: 惑星の公転周期 \(T\) と軌道長半径 \(R\) のデータに対し、LLMは自律的に対数変換(\(\log(T)\) と \(\log(R)\))を実施するコードを生成しました。この分析結果から強い線形相関が見出され、「\(T^2 \propto R^3\)」という非線形な関係式へと探索空間を効果的に絞り込むことに成功しています。
- IGSRによる新規生物学的仮説の実証: RNAポリメラーゼIIのポージング(転写の一時停止)を予測するタスクにおいて、IGSRは「DNAメチル化」を示す項に負の係数が付与された数式を同定しました。これは「DNAメチル化がポージングを抑制する」というこれまでにない新たな仮説の提示であり、その後の実際のウェットラボ(Wet-lab)実験によって正しいことが実証されています。
4. LLMのファインチューニングと強化学習
これまでの章では、プロンプトを活用した探索手法を解説してきましたが、反復回数が増えるにつれてプロンプトが長大化する課題に直面します。この課題を克服し、より高精度な数式を導き出すために、LLM自体のパラメータを直接更新するファインチューニングや強化学習のアプローチが注目を集めています。
コンテキスト爆発からの脱却
プロンプトに過去の数式候補や評価結果を次々と蓄積していく手法は、情報量が多すぎるとLLMの注意力が分散し、探索の方向性がブレてしまう「フィードバックドリフト」を引き起こす危険性があります。この問題に対処するため、QuantEvolverというフレームワークでは、GRPO(Group Relative Policy Optimization)などの強化学習を用いたファインチューニング(RFT: Reinforcement Fine-Tuning)を採用しています。評価結果をテキストとしてプロンプトに残すのではなく、LLMのパラメータ更新という形で経験を直接モデルに定着させることで、コンテキスト長制限による「コンテキスト爆発」を回避しつつ安定した最適化を実現しています。

DiCo Rewardによる探索空間の拡大
強化学習を進める上では、モデルがどのような数式を生成すべきかを「報酬」として設計することが重要です。QuantEvolverでは、純粋な予測精度だけでなく、生成された数式構造の多様性(Diversity)と行動の相補性(Complementarity)を考慮した「DiCo Reward」という独自の報酬を定式化しています。 具体的には、すでに発見されている数式と似た構造を生成した場合はペナルティを与え、まだ見ぬ新しい構造や、既存の数式を補完するような振る舞いを示す数式には高い報酬を与えます。この仕組みにより、モデルが特定の数式パターンに固執することを防ぎ、様々な数式構造を効果的に探索できるようになります。
Symbolic-R1の学習戦略と報酬設計
また、約14.8万件の大規模な数式データセット「SymbArena」を用いてモデルを最適化するSymbolic-R1という手法も登場しています。このデータセットでは、訓練データとテストデータの間で数式の形(スケルトン)が被らないように厳密に分割されており、モデルが学習データをただ暗記してしまう情報漏洩(データリーク)を効果的に防いでいます。
さらに、Symbolic-R1では「Form-GRPO」という強化学習手法を活用し、以下の4つの指標を組み合わせて報酬を計算します。
- Form-Correct: 数式として構文が論理的に正しいか
- Form-Similarity: 正解の数式構造とどれくらい似ているか
- Numerical: 実際のデータに対する予測精度がどれくらい高いか
- Equivalent: 正解と完全に同等の構造をしているか
単に誤差を最小化するだけでなく、構文の正しさや構造の類似度に対する報酬をバランスよくブレンドすることで、構文的に正しくかつ数値的にも正確な数式を効率よく導き出すことが可能になっています。

5. メタ学習および最適化軌跡分析
これまでは数式の形を探索するアプローチを見てきましたが、シンボリック回帰の「探索アルゴリズムそのもの」をLLMに設計させたり、LLMの探索プロセス自体を分析したりする研究も進んでいます。本章では、メタ学習によるアルゴリズムの進化と、LLMが描く探索軌跡の特性について解説します。
メタ学習による選択オペレータの進化
LLM-Meta-SRというフレームワークでは、遺伝的プログラミングにおいてどの数式を次世代に残すかを決める「選択オペレータ」のプログラムコード自体をLLMに記述させます。この進化のプロセスで交差(Crossover)を実施する際、単に平均スコアが高いプログラム同士を親として選ぶと、似たような特徴を持つ親ばかりが選ばれる可能性があります。そこで、各タスクの評価スコアをベクトルとして保持し、要素ごとの最大値を評価する「意味論を考慮した選択(Semantics-Aware Selection)」が導入されています。これにより、あるタスクが得意な親と、別のタスクが得意な親というように、互いの弱点を補い合う相補性のある親同士が効果的に選ばれます。
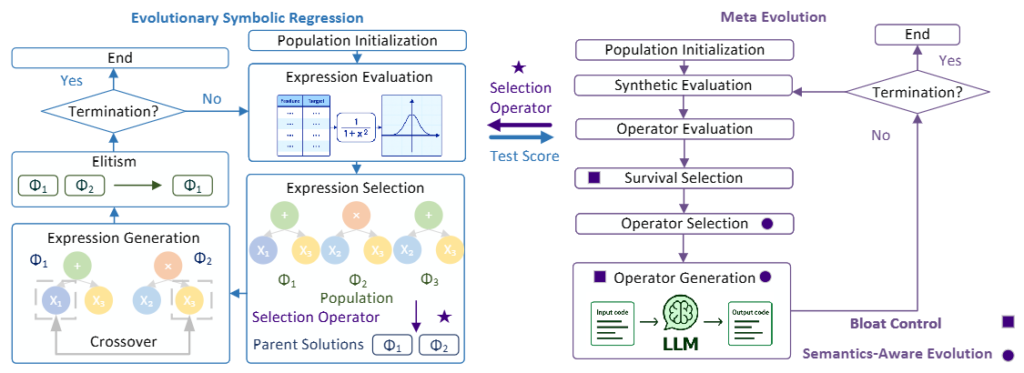
右側は、候補となる選択オペレーターを生成する外側のメタ進化ループを示し、左側は、各候補オペレーターを用いて記号式を進化させ、その性能を評価する内側の記号回帰(SR)ループを示している。(LLM-Meta-SR: In-Context Learning for Evolving Selection Operators in Symbolic Regression より引用)
ブロート(肥大化)制御機構
LLMにコードを生成させると、意味のない冗長な記述が増えてコードが長大化する「ブロート(肥大化)」という現象が発生しやすくなります。これを防ぐため、LLM-Meta-SRでは「多目的生存選択」を導入しています。この機構では、アルゴリズムの性能の高さとコードの短さの両立を目指すパレート優越性を評価の基準としています。さらに、AST(抽象構文木)やデータフローを考慮したコードの類似度指標である「CodeBLEU」を用いて、似たようなコードを持つアルゴリズムにペナルティを与えます。これにより、冗長で肥大化したコードを排除し、簡潔で効果的なオペレータを維持する仕組みが実現されています。
探索軌跡の分析と空間エントロピー
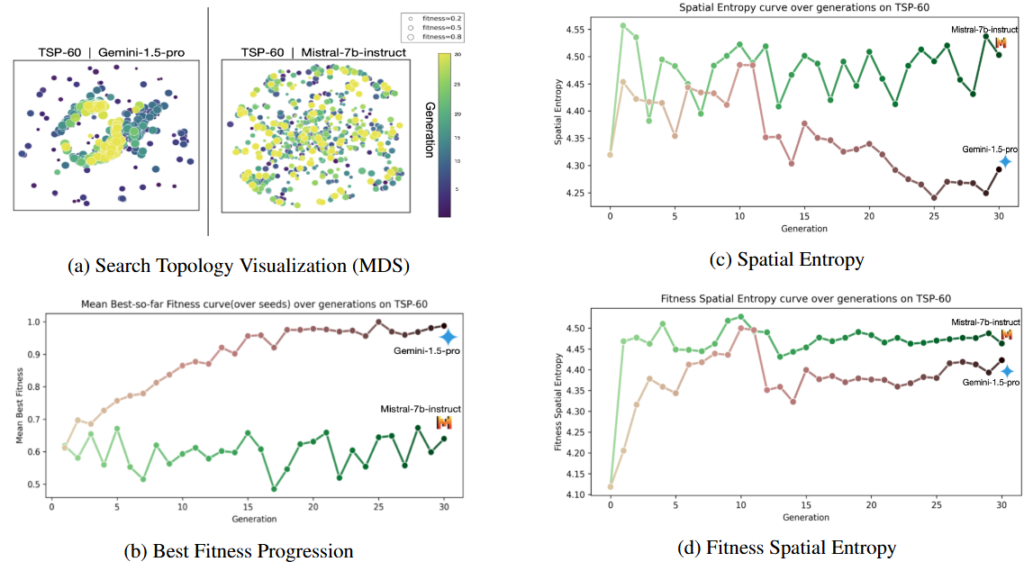
LLMを探索アルゴリズムとして用いる際、「事前の指示だけで一発で解を出す能力(Zero-shot性能)」が高いモデルが、必ずしも反復探索を導く能力に優れているとは限りません。LLMによる数式の変異はランダムな変更ではなく、文脈に強く依存した意味的な変化となるため、単に新規性が高い数式を出すだけでは精度の向上に直結しないからです。
優れたLLMオプティマイザの探索軌跡を分析すると、意味空間上での候補の広がりを示す「空間エントロピー(Spatial Entropy)」や、高精度な候補の集中度を示す「適応度空間エントロピー(Fitness Spatial Entropy)」といった指標が効果的に機能していることが分かります。これらの指標を可視化すると、優れたモデルは探索を局所的な領域に絞り込み(Local Refinement)、小さな改善を継続的に積み重ねていることが確認できます。つまり、真に有効な探索とは、やみくもに新しい形を試すのではなく、有望な領域で着実に数式を洗練させることなのです。
6. Pythonによる実装例
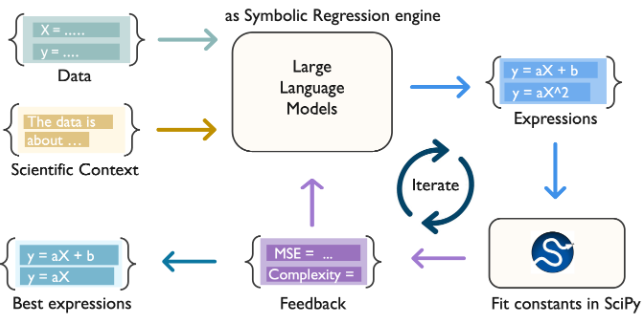
ここでは、大規模言語モデル(LLM)の推論能力と古典的な数値最適化を組み合わせた In-Context Symbolic Regression(ICSR) の仕組みを、実際のコードを追いながら解説します。
ICSRとは
シンボリック回帰(Symbolic Regression)は、データ点の集合 \({(x_i, y_i)}\) から「係数だけでなく数式の構造ごと」を発見する問題です。たとえばデータが \(y = x^3 + x^2 + x\) というルールで生成されていた場合、シンボリック回帰はその数式を推定します。
従来の遺伝的プログラミングによるアプローチは、数式の構造空間を半ランダムに探索するため計算コストが高く、発見した式が解釈しにくい傾向があります。
ICSR(ACL 2024)はこれをLLMで解決します。アプローチは以下の通りです:
- LLM に「データを見て、それらしい数式の形(構造)を提案させる」
- 提案された構造の数値係数だけを SciPy の
curve_fitで最適化する - 良い候補をコンテキストに蓄積し、次の提案の参考にさせる(OPRO スタイル)
- 収束するまで繰り返す
シード生成 ─→ 係数最適化 ─→ スコアリング ─→ プール更新 ─→ LLM提案 ─→ ...
(LLM) (curve_fit) (MSE) (上位k個保持) (OPRO)① セットアップ
# Google Colab の場合は先頭セルで実行
# !pip install google-genai sympy scipy scikit-learn numpy
import os
import re
import numpy as np
import sympy
from sympy import Symbol
from sympy.parsing.sympy_parser import parse_expr
from scipy.optimize import curve_fit
from sklearn.metrics import r2_score
from google import genai
# GEMINI_API_KEY 環境変数から API キーを読み込む
# Colab の場合: from google.colab import userdata; os.environ["GEMINI_API_KEY"] = userdata.get("GEMINI_API_KEY")
_client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
MODEL_NAME = "gemini-3.5-flash"
def _generate(prompt: str) -> str:
resp = _client.models.generate_content(model=MODEL_NAME, contents=prompt)
return resp.text
➁ データの準備
まず、アルゴリズムが探索対象とする訓練データを用意します。ここでは Nguyen-1 ベンチマークの正解式 \(y = x^3 + x^2 + x\) から点を生成します。ICSRはこれらの点しか「見えない」状態で数式を発見します。
def make_data(n=20):
# [-1, 1] の範囲で等間隔に点を生成する
xs = np.linspace(-1, 1, n)
ys = xs**3 + xs**2 + xs # 実際の実験ではここを非公開にする
return np.column_stack([xs, ys])
points = make_data()
print(f"データ形状: {points.shape}") # (20, 2)
print(f"先頭3点: {points[:3]}")
③ シード関数の生成(LLM)
最初のステップとして、LLM にデータ点の一覧を見せ、数式の候補(シード関数)を複数生成させます。この段階では精度より多様性を重視します。
プロンプトのポイントは「係数は c と書くだけ、数値は書かない」という指示です。係数の数値は後の最適化ステップで決定されるため、LLM には数式の構造だけを提案させます。
SEED_PROMPT = """\
I want you to act as a mathematical function generator.
Given a set of points below, come up with 5 potential functions that fit the points.
Focus on diversity rather than accuracy — these are starting points for further optimization.
Available: variable x, coefficient c (no bare numbers), \
operators +, -, *, /, ^, sqrt, exp, log, abs, sin, cos, tan, sinh, cosh, tanh
Points:
{points}
Output only the functions in this format (no explanations):
f1 = ...
f2 = ...
f3 = ...
f4 = ...
f5 = ...\
"""
def parse_functions(text):
"""LLM 出力から関数式の右辺を抽出する"""
matches = re.findall(r'f\d+(?:\([^)]*\))?\s*=\s*(.+)', text)
return [m.strip().rstrip('.,;') for m in matches if m.strip()]
def generate_seed_functions(points):
pts_str = "\n".join([f"({x:.3f}, {y:.3f})" for x, y in points])
prompt = SEED_PROMPT.format(points=pts_str)
return parse_functions(_generate(prompt))
seed_fns = generate_seed_functions(points)
print("LLM が提案したシード関数:")
for i, fn in enumerate(seed_fns):
print(f" f{i+1} = {fn}")
実行例:
LLM が提案したシード関数:
f1 = c * x + c * x^c
f2 = c * exp(c * x) + c
f3 = c * sinh(c * x) + c * cosh(c * x) + c
f4 = c / (c - x) + c
f5 = c * sin(c * x) + c * x^2 + cc はすべて同じ「係数という意味のプレースホルダー」です。次のステップで各 c にユニークな記号を割り当て、数値を最適化します。
④ 係数の最適化
次に各シード関数の係数を最適化します。このステップは2段階です:
- 係数のトークン化:文字列中の
cをc0,c1,c2, … に置換し、それぞれ独立した最適化パラメータにする - curve_fit によるフィッティング:SciPy の
curve_fitでデータ点への当てはめを行う
replace_coeff_tokens では正規表現の語境界 \b を使うことで、cos や cosh の中の c は変換せず、係数として使われている c のみを置換します。
def clean_fn_str(fn_str):
"""LLM 出力の関数文字列を SymPy がパースできる形に正規化する"""
fn_str = fn_str.strip().rstrip('.,;')
if '=' in fn_str:
fn_str = fn_str.split('=', 1)[1].strip()
fn_str = fn_str.replace('^', '**') # ^ を Python の ** に変換
fn_str = re.sub(r'(\d)x', r'\1*x', fn_str) # 2x → 2*x
return fn_str
def replace_coeff_tokens(fn_str):
"""
文字列中の係数トークン 'c' を c0, c1, c2, ... に順番に置換する。
語境界 (\b) を使うことで cos, cosh などには影響しない。
例: "c*cos(c*x) + c" → "c0*cos(c1*x) + c2"
"""
n = [0]
def replacer(m):
result = f"c{n[0]}"
n[0] += 1
return result
return re.sub(r'\bc\b', replacer, fn_str)
def string_to_sympy(fn_str):
"""前処理済みの文字列を SymPy 式に変換する"""
try:
return parse_expr(fn_str)
except Exception as e:
raise ValueError(f"パース失敗: '{fn_str}' -> {e}")
def optimize(fn_str, points, n_restarts=5):
"""
LLMが出力した関数文字列の係数を SciPy curve_fit で最適化する。
- fn_str: 例 "c * exp(c * x) + c"
- returns: (最適化済み SymPy 式, 係数形式の文字列)
"""
cleaned = clean_fn_str(fn_str)
coeff_str = replace_coeff_tokens(cleaned)
expr = string_to_sympy(coeff_str)
x = Symbol('x')
# 'c' で始まる文字の後に数字が続く記号(c0, c1, ...)を係数として取得
coeffs = sorted(
[s for s in expr.free_symbols if re.match(r'^c\d+$', str(s))],
key=lambda s: int(str(s)[1:])
)
if not coeffs:
return expr, coeff_str # 係数なし(定数関数など)
# SymPy 式を NumPy 関数に変換して curve_fit に渡す
f = sympy.lambdify([x] + coeffs, expr, 'numpy')
xs, ys = points[:, 0], points[:, 1]
best_popt, best_error = None, np.inf
# 複数の初期値でリスタートし、最良の結果を採用する
for _ in range(n_restarts):
try:
p0 = np.random.uniform(-5, 5, len(coeffs))
popt, _ = curve_fit(
lambda xv, *c: f(xv, *c), xs, ys,
p0=p0, maxfev=10000
)
pred = f(xs, *popt)
if not np.isfinite(pred).all():
continue
err = float(np.mean((pred - ys) ** 2))
if err < best_error:
best_error, best_popt = err, popt
except Exception:
pass
if best_popt is None:
raise ValueError(f"最適化失敗: {fn_str}")
# 係数を丸めて代入
popt_rounded = np.round(best_popt, 4)
optimized = expr.subs(list(zip(coeffs, popt_rounded)))
return optimized, coeff_str
試しに c * exp(c * x) + c を最適化してみます:
fn_str = "c * exp(c * x) + c"
optimized, coeff_str = optimize(fn_str, points)
print(f"係数形式: {coeff_str}")
print(f"最適化後: {optimized}")
実行例:
係数形式: c0 * exp(c1 * x) + c2
最適化後: -2.5031*exp(-1.1418*x) + 3.2541⑤ スコアリング
最適化した関数の「良さ」を数値化します。ICSR ではスコアが低いほど良い候補です。
def mse_score(expr, points):
"""MSE(平均二乗誤差)でスコアを計算する。低いほど良い。"""
x = Symbol('x')
try:
f = sympy.lambdify(x, expr, 'numpy')
pred = np.asarray(f(points[:, 0]), dtype=float)
if not np.isfinite(pred).all():
return np.inf
return float(np.mean((pred - points[:, 1]) ** 2))
except Exception:
return np.inf
def r2_val(expr, points):
"""R² スコアを計算する。1.0 に近いほど良い(収束判定に使用)。"""
x = Symbol('x')
try:
f = sympy.lambdify(x, expr, 'numpy')
pred = np.asarray(f(points[:, 0]), dtype=float)
if not np.isfinite(pred).all():
return -np.inf
return float(r2_score(points[:, 1], pred))
except Exception:
return -np.inf
sc = mse_score(optimized, points)
r2 = r2_val(optimized, points)
print(f"MSE: {sc:.6f}")
print(f"R²: {r2:.5f}")
⑥ 関数プールの管理
FunctionPool は、これまでに発見した候補関数を上位 max_size 個だけ保持するコンテキストウィンドウです。LLM は次のイテレーションでこのプールを見て、より良い候補を提案します。
プロンプトには「スコアが悪い順(上位)→良い順(下部)」で関数を並べます。こうすることで LLM が「下部ほど良い」という文脈を読み取り、さらに改善された式を提案しやすくなります(OPRO スタイル)。
class FunctionPool:
"""上位 max_size 個の候補関数を保持するプール(CurrentFunctions の簡略版)"""
def __init__(self, max_size=3):
self.pool = [] # [(score, coeff_str, optimized_expr), ...]
self.max_size = max_size
def add(self, coeff_str, optimized_expr, sc):
if not np.isfinite(sc):
return
self.pool.append((sc, coeff_str, optimized_expr))
# スコア昇順(低いほど良い)で保持
self.pool.sort(key=lambda t: t[0])
self.pool = self.pool[: self.max_size]
def get_best(self):
return self.pool[0] if self.pool else None
def build_prompt_section(self):
"""OPRO スタイルのプロンプト用テキスト(スコア降順 = 悪い順)を生成する"""
lines = []
for sc, coeff_str, _ in reversed(self.pool):
lines.append(f"Function: {coeff_str}\nError: {sc:.6f}\n")
return "\n".join(lines)
⑦ 反復改善ループ(全体統合)
すべてのコンポーネントを組み合わせた ICSR のメインループです。
各イテレーションで、プール内の関数と対応するスコアを OPRO スタイルのプロンプトで LLM に提示し、より良い候補を生成させます。
OPRO_PROMPT = """\
I want you to act as a mathematical function generator.
Given the (x, y) points below, propose 5 new functions with lower error than the ones listed.
Points:
{points}
Previous functions (ordered worst to best, lower error is better):
{functions}
Use 'c' for all coefficients (they will be numerically optimized). Use 'x' as variable.
Make the new functions structurally different from the ones above.
Output only the new functions:
f1(x) = ...
f2(x) = ...
f3(x) = ...
f4(x) = ...
f5(x) = ...\
"""
def generate_new_functions(points, pool):
"""プールの内容をプロンプトに組み込み、LLM に新しい候補を生成させる"""
pts_str = "\n".join([f"({x:.3f}, {y:.3f})" for x, y in points])
prompt = OPRO_PROMPT.format(
points=pts_str,
functions=pool.build_prompt_section() + "\nNew Functions: "
)
return parse_functions(_generate(prompt))
def run_icsr(points, n_iterations=10, tolerance=0.9999, pool_size=3):
"""
ICSR メインループ
- n_iterations: 最大反復回数
- tolerance: R² による収束閾値
- pool_size: コンテキストに保持する関数数
"""
pool = FunctionPool(max_size=pool_size)
# --- Step 1: シード関数の生成と最適化 ---
print("=== シード関数の生成 ===")
seed_fns = generate_seed_functions(points)
for fn_str in seed_fns:
try:
optimized, coeff_str = optimize(fn_str, points)
sc = mse_score(optimized, points)
pool.add(coeff_str, optimized, sc)
print(f" {coeff_str} → MSE={sc:.6f}")
except Exception as e:
print(f" [NG] {fn_str}: {e}")
# --- Step 2: 反復改善ループ ---
print("\n=== 反復改善ループ ===")
for i in range(n_iterations):
best = pool.get_best()
if best is None:
print("プールが空です")
break
r2 = r2_val(best[2], points)
print(f"\n[Iter {i + 1}] best = {best[1]} | MSE={best[0]:.6f} | R²={r2:.5f}")
# 収束判定: R² が閾値を超えたら終了
if r2 >= tolerance:
print(f" → 収束!発見した式: {best[2]}")
return best[2]
# LLM に新しい候補を生成させる
new_fns = generate_new_functions(points, pool)
for fn_str in new_fns:
try:
optimized, coeff_str = optimize(fn_str, points)
sc = mse_score(optimized, points)
pool.add(coeff_str, optimized, sc)
print(f" [OK] {coeff_str} → MSE={sc:.6f}")
except Exception as e:
print(f" [NG] {fn_str}: {e}")
best = pool.get_best()
print(f"\n最終結果: {best[2] if best else 'なし'}")
return best[2] if best else None
⑧ 実行
各パーツが揃ったので実行してみましょう。
np.random.seed(42)
points = make_data()
result = run_icsr(points, n_iterations=10, tolerance=0.9999)
if result:
print(f"\n発見した式: {result}")
print(f"簡約化後: {sympy.simplify(result)}")
実行例:
=== シード関数の生成 ===
c0 * x * x + c1 * x + c2 → MSE=0.030015
c0 * exp(c1 * x) + c2 → MSE=0.008777
c0 * sinh(c1 * x) + c2 * cosh(c3 * x) + c4 → MSE=0.000086
c0 / (c1 - x) + c2 → MSE=0.005213
c0 * sin(c1 * x) + c2 * x * x + c3 → MSE=0.030031
=== 反復改善ループ ===
[Iter 1] best = c0*sinh(c1*x) + c2*cosh(c3*x) + c4 | MSE=0.000086 | R²=0.99993
→ 収束!発見した式: 0.5071*sinh(2.0871*x) + 509.7556*cosh(0.0626*x) - 509.7556シード生成の段階で双曲線関数の組み合わせが高い R² を達成し、すぐに収束しています。発見した式は \(x^3 + x^2 + x\) とは異なる表現形式ですが、この範囲では統計的に同等の精度を持ちます。
tolerance を高め(例: 0.99999)、より多くのイテレーションを許可すると、多項式形式の正解式が見つかりやすくなります。
# より厳密な条件で再試行 result = run_icsr(points, n_iterations=10, tolerance=0.99999)
実行例(より厳密な場合):
[Iter 1] best = ... | R²=0.99993
[OK] c0*x**3 + c1*x**2 + c2*x + c3 → MSE=0.000000
[Iter 2] best = c0*x**3 + c1*x**2 + c2*x + c3 | MSE=0.000000 | R²=1.00000
→ 収束!発見した式: 1.0*x**3 + 1.0*x**2 + 1.0*x多項式の形でシードを生成・改善することにより、$x^3 + x^2 + x$ を正確に復元しています。
おわりに
これまで見てきたように、プロンプトの工夫、探索アルゴリズムの統合、強化学習、そしてメタ学習といった様々なアプローチにより、シンボリック回帰は単なるデータ適合から自律的かつ協調的な科学的発見プロセスへと進化を遂げました。
機械学習モデルを科学研究やエンジニアリングの現場で実用化するには、単なる予測精度の高さだけでなく、人間が理解できる「解釈可能性」と、シミュレーション時に破綻しない「物理的妥当性」が不可欠です。ブラックボックスな予測から脱却し、物理法則などのドメイン知識を制約として組み込んで信頼できる法則を導き出すアプローチは、今後さらに重要性を増すでしょう。
実務者におかれては、LLMを単なるテキストやコードの生成器としてではなく、専門知識を活用してシステム全体を安全な探索へと導くエージェントとして組み込む視点が、次世代のAI開発において強力な武器となるはずです。
More Information
- arXiv:2410.17448, Samiha Sharlin et al., 「In Context Learning and Reasoning for Symbolic Regression with Large Language Models」, https://arxiv.org/abs/2410.17448
- arXiv:2503.06512, Zhilong Song et al., 「LLM-Feynman: Leveraging Large Language Models for Universal Scientific Formula and Theory Discovery」, https://arxiv.org/abs/2503.06512
- arXiv:2505.18602, Hengzhe Zhang et al., 「LLM-Meta-SR: In-Context Learning for Evolving Selection Operators in Symbolic Regression」, https://arxiv.org/abs/2505.18602
- arXiv:2508.09897, Yingfan Hua et al., 「Finetuning Large Language Model as an Effective Symbolic Regressor」, https://arxiv.org/abs/2508.09897
- arXiv:2603.19241, Yue Wu et al., 「Engineering-Oriented Symbolic Regression: LLMs as Physics Agents for Discovery of Simulation-Ready Constitutive Laws」, https://arxiv.org/abs/2603.19241
- arXiv:2604.19440, Xinhao Zhang et al., 「What Makes an LLM a Good Optimizer? A Trajectory Analysis of LLM-Guided Evolutionary Search」, https://arxiv.org/abs/2604.19440
- arXiv:2605.03101, Hao Liu et al., 「Programmatic Context Augmentation for LLM-based Symbolic Regression」, https://arxiv.org/abs/2605.03101
- arXiv:2605.15412, Lingzhe Zhang et al., 「From Feedback Loops to Policy Updates: Reinforcement Fine-Tuning for LLM-Based Alpha Factor Discovery」, https://arxiv.org/abs/2605.15412
- arXiv:2605.29184, Evgeny S. Saveliev et al., 「Influence-Guided Symbolic Regression: Scientific Discovery via LLM-Driven Equation Search with Granular Feedback」, https://arxiv.org/abs/2605.29184
関連記事

PySR: シンボリック回帰とは何か?
シンボリック回帰(Symbolic Regression、記号回帰とも呼ばれます)は、データを説明する数式を自動的に見つけ出す機械学習手法です。この手法では、関数の形式を事前に決めることなく、与えられたデータに最も合う数 […]