Skills-Coach: LLMエージェントスキルの自動進化フレームワーク

LLMベースのエージェント開発において、「スキル」は特定のタスクを実行するための機能拡張モジュールとして広く利用されています。しかし、現状のスキルエコシステムには大きな課題があります。個々のスキルが局所的な問題解決に特化して設計されているため、機能の「断片化」が生じています。その結果、複雑なタスクの要件を十分に満たせず、複数のスキルを統合する際に思わぬボトルネックが発生することが少なくありません。
こうした壁を打ち破るべく提案されたのが、エージェントが自律的にスキルの能力境界を探索し、人間の介入なしに自己進化させるフレームワーク「Skills-Coach」です。
この記事では、このSkills-Coachが「境界を探索するタスクをどう自動生成するか」「スキルをどう自己進化させるか」「スキル能力をどう効果的に評価するか」という3つの疑問をどのように解決しているのかを紐解きます。
1. Skills-Coachを構成する4つのコアモジュール
Skills-Coachは、スキルの評価から改善までのプロセスを、人間の介入なしに自動の閉ループとして実行する4つのコアモジュールで構成されています。それぞれの役割と技術的な仕組みを順に見ていきます。
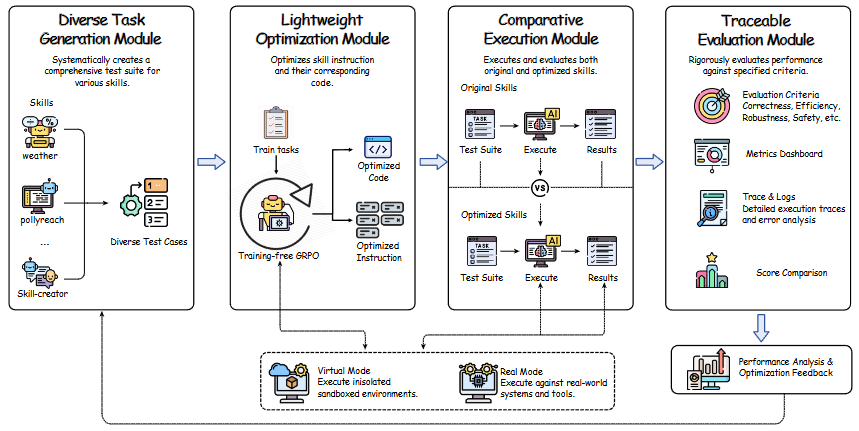
タスク生成モジュール (Diverse Task Generation)
このモジュールは、対象となるスキルの仕様書(SKILL.md や README.mdなど)を解析し、スキルの能力境界を探索するための包括的なテストスイートを自動で生成します。単調なパターンの繰り返しを避けるため、テストケースは以下の3つの難易度に階層化され、様々なシナリオを網羅します。
- 標準タスク: 基本的なファイル処理など、日常的で標準的な操作を検証。
- 高度なタスク: 複数ステップにまたがる複雑なワークフローや、異常な入力データの処理などをテスト。
- 境界タスク: リソースの制約や無効な入力など、システムが限界を迎える極端な条件を設定し、スキルの運用限界をテスト。
軽量最適化モジュール (Lightweight Optimization)
生成されたタスクのテスト結果をもとに、スキルの改善を自動で進める中核エンジンです。計算コストが膨大になりがちな従来の勾配ベース(パラメータ更新型)の最適化に代わり、LLM自身の推論能力を活用する手法「Training-Free GRPO」を採用しています。
最適化は、以下の2つの経路で並行して進められます。
- 命令最適化経路: プロンプトや指示書の品質を反復的に改善し、LLMがタスクをより正確に理解できるようにする。
- コード最適化経路: 入力検証の追加やエラーの自動修正など、実行コードそのものを洗練させる。
このアプローチにより、何時間もかかっていた最適化の処理を数分に短縮しつつ、少ないデータで高い汎用性を実現しています。
比較実行モジュール (Comparative Execution)
独立した隔離環境において、元のスキルと最適化されたスキルの双方をテストタスク上で実行し、結果を客観的に比較・記録する役割を担います。実際の運用に合わせた柔軟なテスト環境を提供するため、2つのモードをサポートしています。
- 現実モード (Real mode): 実際の環境でスキルを展開し、出力ファイルやエラーメッセージを直接評価。
- 仮想モード (Virtual mode): 実際のコード実行をバイパスし、評価基準に関連するキーワードの有無やハッシュ乱数からタスクの完了を推定。
また、テスト中にタスクが失敗した場合でも、システムを停止させることなく部分的な出力やエラーの詳細を保存して次のタスクへ進む「フォールトトレランス(Fail-Safe strategy)」を備えており、評価プロセスの中断を防ぎます。
追跡可能な評価モジュール (Traceable Evaluation)
最後に、実行結果を多角的に採点し、最適化されたスキルを最終的に採用するかどうかの決定を下します。評価の信頼性を高めるため、以下の5つのコア原則に基づいた厳格な判定基準を設けています。
- 採点の客観性: 実行結果から決定論的に採点し、再現性を担保
- 基準の一貫性: 新旧バージョンに対して全く同じ公平な比較基準を適用
- 分析の深さ: 表面的な数値だけでなく、失敗の根本原因まで特定
- 決定の厳密性: 主観を排し、明確な数学的ルールに基づいて採択を決定
- 解釈可能性: すべての決定に対して、エビデンスを伴う詳細なレポートを生成
評価プロセスは、通常はLLMを用いた深い分析によって進められます。ただし、APIのタイムアウトなどでLLMが利用できない状況に陥った場合は、キーワードマッチングや構造分析などを用いたルールベースのチェック(ヒューリスティックモード)へと自動的に切り替わる仕組み(フォールバック)が組み込まれており、評価の堅牢性をしっかりと担保しています。
2. 8つの評価次元と個別の評価指標
前章で触れた「追跡可能な評価モジュール」や「タスク生成モジュール」で用いられる、スキルの品質を採点するための具体的な評価基準です。以下の8つの次元と、それぞれに紐づく個別の評価指標に基づいて厳格に採点されます。
| 評価軸 | 評価基準 |
| 構造の完全性と構成 (Structural Completeness & Organization) | 1. 目的と目標を説明する、ドキュメント冒頭の明確な導入や概要 2. 完全な環境構築を伴う、インストールやセットアップの手順 3. すべてのコマンドと機能を詳述した、包括的な使用方法のセクション 4. 少なくとも3つの異なる現実的なシナリオを含む、複数の具体的な実行例 5. 設定可能なすべてのオプションを網羅した、構成(パラメータ)のセクション 6. FAQ用の専用セクションを設けた、トラブルシューティングとエラー処理 7. 基本概念から高度な概念へと至る、論理的な内容の進行 |
| 実用性と学習のしやすさ (Practical Usability & Learnability) | 1. 明確な案内キーワード(first, then, next など)を用いた、初心者向けのステップバイステップガイド2. 実際のコマンド( $, python, bash など)を用いた、そのままコピー&ペーストできる具体例3. 依存関係と必要な知識を明確に記載した、明示的な前提条件 4. 注意を引くマーカー( warning, note, important など)を用いた、よくある落とし穴のドキュメント化5. シンプルなものから高度なものへ、段階的に複雑さが増すサンプルの提示 6. クイックスタートガイド、または最小限の動作確認用(Minimal working example)セクション |
| サンプルの品質と網羅性 (Example Quality & Coverage) | 1. 完全に実行可能なコードブロックを伴う、少なくとも3つの異なる実際の実行例 2. 単なるタスクのバリエーションではなく、様々なシナリオをカバーするユースケース 3. 実行結果のマーカー( output:, result:, =>, -> など)を使用した、期待される出力の提示4. エッジケースや極端なシナリオを示す、境界条件のサンプル 5. 例外と障害の処理を示す、エラー処理のシナリオ 6. 実世界のアプリケーションを想定した、複雑なマルチステップのワークフロー |
| 技術的な深さと正確さ (Technical Depth & Accuracy) | 1. 適切なキーワード(parameter, option, flag)でドキュメント化された、すべてのパラメータとオプション2. 戻り値と出力形式の仕様(データ型やJSON構造など) 3. 関連する場合の、パフォーマンス特性への言及 4. 明示的にリストされた、明確な制限事項とシステム制約 5. 他のシステムとの統合に関する説明とデモンストレーション 6. 2つ以上の専門的な技術用語( API, CLI, SDK など)の正しい使用 |
| 明確さと読みやすさ (Clarity & Readability) | 1. 平均文長が30語未満の、明確で簡潔な文章 2. 見出しのレベルが統一された、一貫したフォーマットとスタイル 3. 少なくとも3つの見出し、リスト( - または *)、およびコードブロックの適切な使用4. 曖昧な表現や誤解を招く表現を避けた、明確な記述 5. 簡潔すぎず冗長すぎない、適切な詳細レベル(500〜15,000文字程度) 6. 中見出し( ##)や小見出し(###)を使用した、優れた視覚的階層構造 |
| コマンドカバレッジの完全性 (Command Coverage Completeness) | 1. サンプルに示されたすべてのコマンドがドキュメントで説明されていること 2. 各コマンドのすべてのフラグとオプションがドキュメント化されていること 3. コマンドの構文が正しい形式で明確に示されていること 4. 各コマンドを使用するタイミングや状況(コンテキスト)が説明されていること 5. 複数のコマンド間の関係性が明確にされていること 6. ドキュメント化されていない機能や隠し機能が存在しないこと |
| エラー処理とトラブルシューティング (Error Handling & Troubleshooting) | 1. 修正方法とともにリストされた、よくあるエラーと解決策 2. 意味と発生状況を明確にする、エラーメッセージの詳細な説明 3. 診断方法と専用コマンドを伴う、デバッグのヒント 4. 既知の問題と回避策(ワークアラウンド)のドキュメント化 5. サポート窓口への連絡やバグレポートの手順の提供 6. 構成が正しいかを確認するための検証手順 |
| 高度なシナリオとベストプラクティス (Advanced Scenarios & Best Practices) | 1. 本番環境を想定した複雑な例を伴う、高度なユースケースとパターン 2. 推奨を示すキーワード( best practice, recommended, tip など)を使用したベストプラクティス3. 適用可能な場合の、パフォーマンス最適化のヒント 4. 関連する場合の、セキュリティに関する考慮事項への言及と説明 5. 他のツールと連携・結合させる方法を示す、統合パターンの提示 6. 実践的なシナリオの全容を示す、実世界のワークフロー例 |
3. 実験設定と実証結果
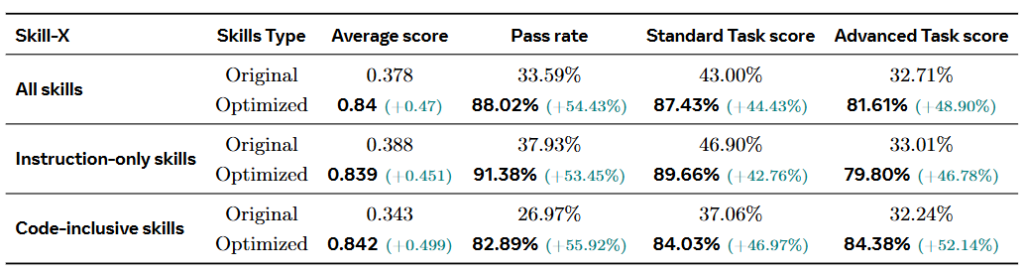
ベンチマーク「Skill-X」における大幅な性能向上
Skills-Coachの実力を検証するため、主要な開発者プラットフォームから収集した48のスキルを含むベンチマークデータセット「Skill-X」を用いた評価が実施されました。このデータセットは、プロンプト指示のみで構成される「命令のみのスキル」29個と、実行可能なスクリプトを伴う「コードを含むスキル」19個で構成されています。
実験は、最適化の反復回数(エポック数)を3、各回でのバリアント生成数(group_size)を3という設定で進められました。最適化のプロセスを経た結果、明確な性能の向上が確認されています。
具体的な成果は以下の通りです。
- 全体性能の劇的な底上げ: 最適化の結果、全体の合格率は33.59%から88.02%へと急上昇し、平均スコアも0.378から0.84へと大幅に向上。
- コードを含むスキルでの顕著な成長: 「命令のみのスキル」と比較して、「コードを含むスキル」において相対的な向上がより顕著に現れました。これは複雑な論理処理を要する場面で、最適化機能が強く作用することを示している。
- 高度なタスクへの高い適応力: 基本的な「標準タスク」よりも、複雑なワークフローを伴う「高度なタスク」において、より大きなスコアの伸びを記録。
なお、これらの性能評価は単なる表面的なチェックではありません。生成されたすべてのサンプルは、構造の完全性やエラー処理能力など、8つの評価次元と51の個別の評価指標に基づいて厳密に品質採点されています。
ケーススタディと最適化リソースの配分
実際の最適化プロセスがどのように機能するのか、Pollyreachというスキルを例にしたケーススタディを紐解きます。このスキルの最適化レポートでは、「タスクごとの内訳(Per-Task Breakdown)」と「能力境界分析(Capability Boundary Analysis)」という2つの主要な分析次元で、改善の成果が可視化されました。
同事例の「高度なタスク」では、当日配達機能(same-day delivery functionalities)の処理などが組み込まれました。ここでは基本的な実行確認にとどまらず、「JSON形式での正確な出力」や「厳格な入力検証」が要求され、実践的な環境に耐えうる堅牢性が評価されています。
さらに、実験全体を通じた実務的な教訓として、最適化には「収穫逓減(diminishing returns)」の傾向があることが示されました。 すでに完璧に近いスコアを持つスキルに対して追加で最適化リソースを投資しても、得られる効果は非常に薄くなります。そのため、初期性能の低いスキルにリソースを集中させることで、高い費用対効果を得ながらシステム全体の能力を効率よく引き上げることができます。

4. Skill Sources in Skill-X
前章で言及したベンチマークデータセット「Skill-X」を構成する全48のスキルの情報源一覧です。これらのスキルは、ClawHub や Anthropic、Vercel Labsなど、主要な開発者プラットフォームから実際に収集されたものであり、実験結果の高い実用性と普遍性を担保しています。
| skill name | source | rank in source |
|---|---|---|
| self-improving-agent | clawhub.ai | 1 |
| ontology | clawhub.ai | 3 |
| self-improving-proactive-agent | clawhub.ai | 4 |
| weather | clawhub.ai | 8 |
| multi-search-engine | clawhub.ai | 9 |
| polymarket-trade | clawhub.ai | 10 |
| pollyreach | clawhub.ai | 11 |
| admapix | clawhub.ai | Common |
| agent-browser-clawdbot | clawhub.ai | Common |
| byterover | clawhub.ai | Common |
| nano-banana-pro | clawhub.ai | Common |
| obsidian-1-0-0 | clawhub.ai | Common |
| rss-daily-digest | clawhub.ai | Common |
| self-evolving-skill | clawhub.ai | Common |
| stock-analysis | clawhub.ai | Common |
| algorithmic-art | github.com/anthropics/skills | Common |
| brand-guidelines | github.com/anthropics/skills | Common |
| canvas-design | github.com/anthropics/skills | Common |
| doc-coauthoring | github.com/anthropics/skills | Common |
| docx | github.com/anthropics/skills | Common |
| frontend-design | github.com/anthropics/skills | Common |
| internal-comms | github.com/anthropics/skills | Common |
| mcp-builder | github.com/anthropics/skills | Common |
| github.com/anthropics/skills | Common | |
| pptx | github.com/anthropics/skills | Common |
| skill-creator | github.com/anthropics/skills | Common |
| slack-gif-creator | github.com/anthropics/skills | Common |
| theme-factory | github.com/anthropics/skills | Common |
| web-artifacts-builder | github.com/anthropics/skills | Common |
| webapp-testing | github.com/anthropics/skills | Common |
| xlsx | github.com/anthropics/skills | Common |
| composition-patterns | github.com/vercel-labs/agent-skills/tree/main/skills | Common |
| deploy-to-vercel | github.com/vercel-labs/agent-skills/tree/main/skills | Common |
| react-best-practices | github.com/vercel-labs/agent-skills/tree/main/skills | Common |
| react-native-skills | github.com/vercel-labs/agent-skills/tree/main/skills | Common |
| react-view-transitions | github.com/vercel-labs/agent-skills/tree/main/skills | Common |
| vercel-cli-with-tokens | github.com/vercel-labs/agent-skills/tree/main/skills | Common |
| vercel-react-best-practices | github.com/vercel-labs/agent-skills/tree/main/skills | Common |
| web-design-guidelines | github.com/vercel-labs/agent-skills/tree/main/skills | Common |
| find-skills | skills.sh | 1 |
| remotion-best-practices | skills.sh | 5 |
| microsoft-foundry | skills.sh | 6 |
| azure-ai | skills.sh | 7 |
| azure-deploy | skills.sh | 8 |
| azure-prepare | skills.sh | 9 |
| azure-diagnostics | skills.sh | 10 |
| browser | skills.sh | Common |
| ui-ux-pro-max | skills.sh | Common |
おわりに
これまで見てきたように、「Skills-Coach」は人間の介入を一切必要とせず、LLMベースのエージェントのスキルを自律的に自己進化させる、包括的かつ強力なフレームワークです。
従来の開発現場で大きな課題となっていた、機能が局所化・断片化したスキルエコシステムによる統合時のボトルネックを効果的に解消します。これにより、単なるツールの寄せ集めにとどまらず、実際の稼働環境における複雑な要求にもしっかりと耐えうる、堅牢なアプリケーションの構築を力強く後押ししてくれます。
エージェント開発の規模が日々拡大していく中で、自律的なスキルの最適化は欠かせないアプローチになっていくでしょう。本記事が、皆さまの開発や研究のプロセスを前進させる一助となれば幸いです。
More Information
- arXiv:2604.27488, Yu Tian et al., 「Skills-Coach: A Self-Evolving Skill Optimizer via Training-Free GRPO」, https://arxiv.org/abs/2604.27488
関連記事

Large Concept Models: 大規模概念モデルとは何か?
近年、大規模言語モデル(LLM)は人工知能分野に革命をもたらし、多くの自然言語タスクにおいて事実上のデファクト・スタンダードとなっています。しかし、現在のLLMは、単語単位で入力と出力を処理するという点で、人間の情報分析 […]

RecursiveMAS: 潜在空間の再帰による次世代マルチエージェント協調
現在、マルチエージェントシステム(MAS)において、エージェント間で「テキスト」を介して情報をやり取りする手法が一般的ですが、これが推論レイテンシ(遅延)を増大させる主な要因となっています。他のエージェントのテキスト出力 […]

コルモゴロフ・アーノルド・ネットワークのアーキテクチャ: 基礎と応用
長年にわたり、多層パーセプトロン(Multi-Layer Perceptron, MLP)は、回帰分析、関数近似、パターン認識といった様々なタスクで中心的な役割を果たしてきました。しかし、その一方で、MLPにはいくつかの […]