YOLO26: 次世代のエッジAI物体検出
2026年1月、Ultralytics社はYOLOシリーズの最新版となる「YOLO26」をリリースしました。YOLOv8やYOLO11といった歴代モデルの正統進化でありながら、今回の設計思想は「エッジデバイスでの推論効率」へと劇的なシフトを遂げています。
これまで、エッジAI開発の現場では、NMS(Non-Maximum Suppression)などの後処理が引き起こす「推論レイテンシの変動」や、学習時と実機動作時のパフォーマンス乖離である「Export Gap」が大きな課題でした。YOLO26は、NMSフリーの完全なエンドツーエンド学習を採用することでこれらのボトルネックを解消し、常に一定の応答速度を保証する「決定的なレイテンシ(Deterministic Latency)」を実現しています。
本記事では、エッジAIの新たな標準となりうるYOLO26について、その革新的なアーキテクチャの変更点から、実際のパフォーマンスへの影響、そしてPythonを用いた具体的な実装方法までを詳しく解説します。
1. YOLOシリーズの進化とYOLO26の位置付け
YOLO(You Only Look Once)の歴史は、そのままリアルタイム物体検出の進化の歴史と言っても過言ではありません。2015年の初代登場から約10年、その変遷は大きく3つの時代に分類できます。
これまでの変遷:3つの時代
まず、Foundational Era (v1-v3) です。ここでは「画像をグリッド分割して一度に推論する」というYOLOの基本概念が確立され、リアルタイム検出の可能性を示しました。続くCommunity Expansion Era (v4-v7) では、CSP(Cross-Stage Partial)接続の導入や、「Bag-of-Freebies」と呼ばれる学習テクニックの集大成により、実用的な精度と速度のバランスが追求されました。
そして直近の Modern Unified Era (v8-v13) です。ここではアンカーフリー化や、検出・セグメンテーション・姿勢推定を1つのフレームワークでこなすマルチタスク性能が飛躍的に向上しました。しかし、この進化の過程で、精度向上と引き換えにある「副作用」が生じていました。それが、DFL (Distribution Focal Loss) のような複雑な演算処理の採用です。これらはGPU上では高速ですが、エッジデバイス(NPUやCPU)への実装時には量子化が難しく、理論値通りの速度が出ない「Export Gap(実装ギャップ)」を生む原因となっていました。
| モデル | Backbone | Neck | Head | タスク | アンカー | 損失関数 (Loss) | 後処理 | 主な革新と貢献 |
| YOLOv1 (2015) | Darknet-24 | なし | Coupled | 物体検出 | なし | SSE (Sum) | NMS | リアルタイム物体検出を可能にした、統合されたシングルステージ回帰フレームワーク。 |
| YOLOv2 (2016) | Darknet-19 | Pass-through | Coupled | 物体検出 | あり | SSE | NMS | アンカーボックス、バッチ正規化、およびRecallと小型物体検出を向上させるpassthrough層を導入。 |
| YOLOv3 (2018) | Darknet-53 | Multi-Scale | Coupled | 物体検出 | あり | BCE + SSE | NMS | 小型物体の位置特定を強化するための、マルチスケール特徴量予測戦略を導入。 |
| YOLOv4 (2020) | CSPDarknet53 | PAN | Coupled | 物体検出 | あり | CIoU + BCE | NMS | 速度と精度の最適なトレードオフを実現するため、CSPを統合したデータ拡張(Augmentation)を採用。 |
| YOLOv5 (2020) | CSPDarknet | PAN | Coupled | 物体検出 | あり | GIoU/CIoU + BCE | NMS | PyTorchベースのモジュール設計。デプロイを容易にするための自動アンカー最適化を搭載。 |
| YOLOv6 (2022) | EfficientRep | PAN | Decoupled | 物体検出 | あり | SIoU / Varifocal | NMS | 産業用推論の効率化(高スループット)を実現する再パラメータ化(Re-parameterized)畳み込みを採用。 |
| YOLOv7 (2022) | E-ELAN | CSP-PAN | Lead + Auxiliary | 物体検出 | あり | CIoU + BCE | NMS | E-ELAN、ディープスーパービジョン、精度と効率を向上させるOTAラベル割り当てを導入。 |
| YOLOv8 (2023) | C2f | PAN | Decoupled | 検出、セグメンテーション、姿勢推定 | なし | BCE + CIoU + DFL | NMS | アンカーフリーのDecoupled Headにより、統一されたマルチタスク検出フレームワークを実現。 |
| YOLOv9 (2024) | GELAN | PAN | Decoupled | 物体検出 | なし | BCE + CIoU + DFL | NMS | 深層ネットワークの情報ボトルネックを克服するため、プログラム可能勾配情報(PGI)とGELANを導入。 |
| YOLOv10 (2024) | GELAN | PAN | Decoupled | 物体検出 | なし | BCE + CIoU + DFL | NMS-Free | Dual-Label AssignmentによるNMS不要の推論を実現。GELANにPartial Self-Attentionを統合。 |
| YOLOv11 (2024) | C3k2 | PAN | Decoupled | 検出、セグメンテーション、姿勢推定 | なし | BCE + CIoU + DFL | NMS | C2PSAベースの特徴精製を採用。後処理には依然として標準的なNMSを使用。 |
| YOLOv12 (2025) | Flash Backbone + Area Attention | PAN | Decoupled | 物体検出、セグメンテーション | なし | BCE + CIoU + DFL | NMS | 計算効率を維持しつつ、長距離の依存関係を捉えるArea Attention (A2) を使用。マルチタスク性能を向上。 |
| YOLOv13 (2025) | Hyper-Net | PAN | Decoupled | 検出、セグメンテーション、姿勢推定 | なし | BCE + CIoU + DFL | NMS | iMoonLabによるサードパーティリリース。関係推論と複雑なシーン理解のためのハイパーグラフ空間モデリングを採用。 |
| YOLOv26 (2026) | CSP-Muon (エッジ最適化CNN) | PAN | Decoupled (1対1) | 検出、セグメンテーション、姿勢推定、OBB | なし | STAL + ProgLoss | NMS-Free | エッジ最適化。1対1のラベル割り当てによるDFLフリー学習。低遅延なネイティブNMSフリーヘッド。CPUおよびエッジへの書き出しに最適化。 |
YOLO26のパラダイムシフト:複雑性から「決定論的」な推論へ
YOLO26は、これまでの「複雑化してでも精度を稼ぐ」トレンドからの脱却を図りました。最大の特長は、NMS(Non-Maximum Suppression)フリーの完全なエンドツーエンド学習への移行です。
従来のYOLO(v8やv11など)は、モデルが出力した大量の重複ボックスを、後処理(NMS)でフィルタリングする必要がありました。これに対しYOLO26は、学習段階で「1つの物体につき1つのボックス」を出力するように最適化されています。これにより、推論時の後処理演算が不要になるだけでなく、画像の複雑さに依存せず常に一定の処理時間を保証する「決定的なレイテンシ(Deterministic Latency)」を実現しました。
つまりYOLO26は、単なるバージョンの更新ではなく、「GPU上のベンチマークスコア」よりも「エッジデバイスでの実効速度」を最優先するという、明確なパラダイムシフトを体現したモデルと言えます。
2. YOLO26のアーキテクチャ詳解
YOLO26が目指したのは、単なる精度の向上ではなく、エッジデバイスにおける「理論値と実効速度のギャップ(Export Gap)」の解消です。そのために刷新されたアーキテクチャの要点を見ていきます。
NMSフリーのエンドツーエンド推論 (NMS-Free End-to-End)
YOLO26の最大の特徴は、推論パイプラインからNMS(Non-Maximum Suppression)を完全に排除した点です。 従来モデルでは、ニューラルネットワークが大量の重複する候補ボックスを出力し、CPUによる後処理(NMS)でそれらを間引く必要がありました。この処理は画像内の物体数によって計算時間が変動するため、システムの応答時間を予測しにくいという課題がありました。
YOLO26では、学習段階で「1つの物体に対して1つのボックス」のみを予測するよう最適化されています(One-to-One Head)。これにより、入力から出力までが単一のストリームとなり、画像の混雑具合に左右されない「決定的なレイテンシ (Deterministic Latency)」を実現しました。これは、厳密なリアルタイム性が求められるロボティクス制御などにおいて画期的な利点となります。
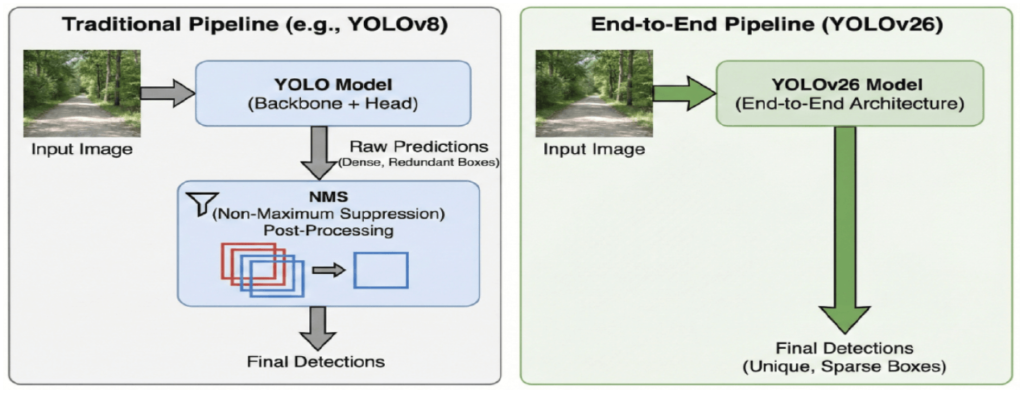
DFL (Distribution Focal Loss) の排除と直接回帰
エッジデバイスでの高速化を徹底するため、近年のYOLO(v8〜v11)で標準だったDFL(Distribution Focal Loss)を排除し、直接回帰(Direct Regression)へ回帰しました。
DFLは位置推定の不確実性を扱うことで精度を向上させますが、その代償としてSoftmax演算や積分計算といった複雑な処理を必要とします。これらはGPUでは高速でも、エッジAIで使われるNPUやDSPでは量子化が難しく、大きなボトルネックとなっていました。YOLO26はこの足かせを取り除くことで、CPU推論速度を最大43%向上させています。
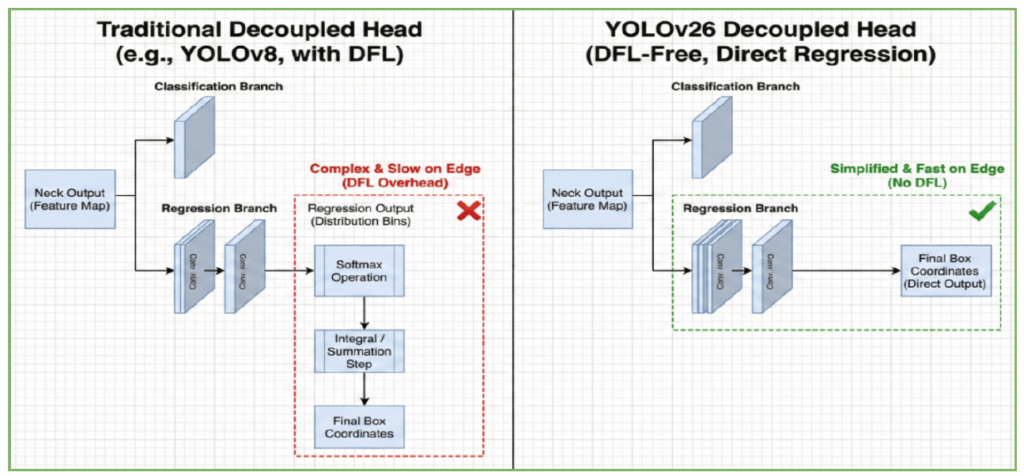
トレーニングの安定化技術 (MuSGD, STAL, ProgLoss)
アーキテクチャを簡素化(DFLやNMSの排除)すると、通常は学習の難易度が上がり、精度維持が困難になります。これを補うため、YOLO26では以下の3つの先進的な学習技術が導入されました。
- MuSGD (Momentum-Unified SGD): LLM(大規模言語モデル)の学習手法に着想を得た新しいオプティマイザです。SGDとMuonオプティマイザを組み合わせることで、勾配の消失を防ぎ、軽量なバックボーンでも安定した収束を実現します。
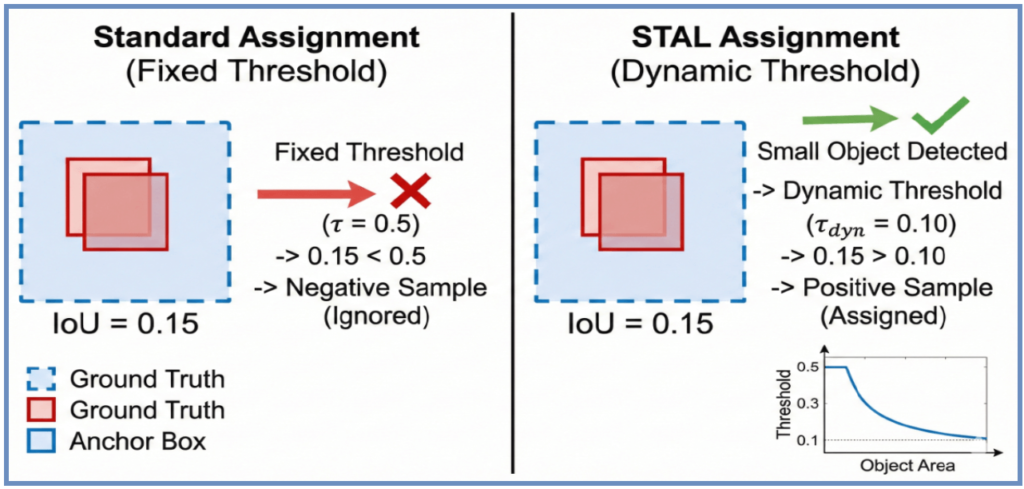
- STAL (Small-Target-Aware Label Assignment): 小さな物体に対する検出精度を向上させるための動的なラベル割り当て技術です。物体のサイズに応じてIoUの閾値を自動調整することで、従来は見逃されがちだった微細なターゲット(画面の1%未満など)に対しても適切な学習シグナルを送ります。
- ProgLoss (Progressive Loss Balancing): 学習のフェーズに応じて、損失関数の重みを動的に変化させる技術です。学習初期は「分類(何であるか)」を重視して学習を安定させ、終盤は「回帰(どこにあるか)」に重みを置くことで、DFLなしでも高い位置特定精度を叩き出します。
3. パフォーマンスと技術的利点
YOLO26が達成した成果は、単なるスペック上の数値向上にとどまりません。それは、これまで実用化の壁となっていた「速度と精度の厳しいトレードオフ」を再定義し、エッジAIの実装要件を根本から覆すものです。
推論速度と精度のトレードオフ改善:新たなパレートフロント
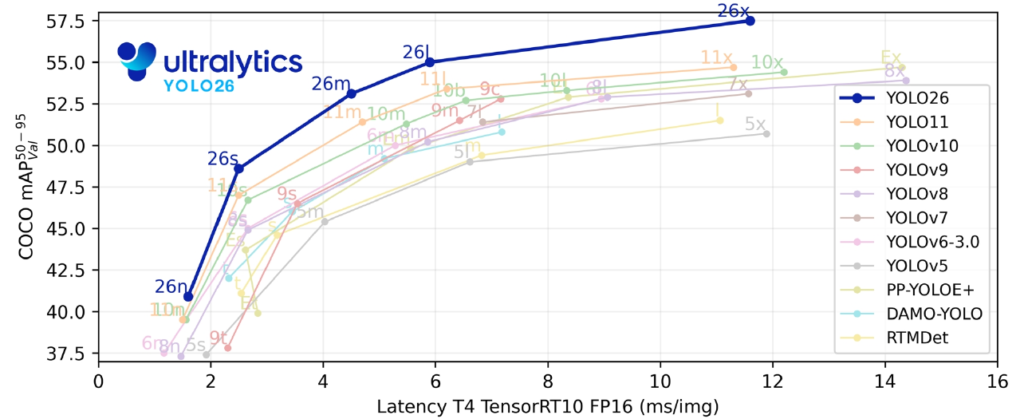
公式ベンチマークの結果を見ると、YOLO26がオブジェクト検出における新たな基準(パレートフロント)を形成していることは一目瞭然です。 具体的には、横軸にレイテンシ、縦軸に精度(mAP)をとったグラフにおいて、YOLO26の曲線はYOLOv5〜11や、RTMDet、DAMO-YOLOといった競合モデルの「左上(より速く、より高精度)」に位置しています。
- Nanoモデル (26n): わずか約1.7ms(CPU ONNX)の推論速度で40.9 mAPを記録し、超軽量モデルの常識を覆しました。
- Extra-Largeモデル (26x): 57.5 mAPという高精度を維持しながらリアルタイム性を確保しており、サーバーサイドの重厚なモデルに匹敵する性能をエッジで発揮します。
エッジデバイスでの優位性:CPU推論の高速化
MLエンジニアにとって最もインパクトがあるのは、GPUを持たないデバイスでのパフォーマンス向上でしょう。 YOLO26は、NMSの除去とDFL(Distribution Focal Loss)の廃止により、計算コストの高いSoftmax演算や積分処理を削減しました。これにより、整数演算が中心となるNPUや、ラズベリーパイ、モバイル端末のCPUにおいて、従来のNMSベースのモデルと比較して最大43%の推論速度向上を実現しています。
これは、学習済みのモデルを実機にデプロイした際に発生しがちな「理論値が出ない」という「Export Gap」の問題を、アーキテクチャレベルで解決したことを意味します。
決定的なレイテンシ (Deterministic Latency)
自動運転や産業用ロボット、医療機器などのミッションクリティカルな領域では、「平均速度」よりも「最悪実行時間」の保証が求められます。 従来のYOLOは、検出された物体の数に応じてNMSの後処理ループ回数が変動するため、混雑したシーンでは推論時間が伸びるリスクがありました。
対して、エンドツーエンドのYOLO26は入力画像の内容に関わらず、推論パイプラインが常に一定の計算量で完了します。この「決定的なレイテンシ (Deterministic Latency)」の特性により、エンジニアはシステムの応答時間を厳密に設計できるようになり、安全性が最優先されるアプリケーションへの導入障壁が大きく下がりました。
4. 様々なビジョンタスクへの対応
YOLO26は、単一の物体検出モデルという枠を超え、あらゆるビジョンタスクをカバーする統合フレームワークとして設計されています。すべてのタスクにおいて、前述の「NMSフリー・エンドツーエンドアーキテクチャ」が適用されており、エッジデバイス上で一貫した高速推論と「決定的なレイテンシ」を提供します。
標準でサポートされるタスク
YOLO26ファミリーは、以下のタスクにおいて独自の最適化が施されています。
- インスタンスセグメンテーション: 新たな「マルチスケール・プロトモジュール」とセマンティック損失関数の導入により、推論速度を落とすことなくマスク生成の品質が向上しました。
- 姿勢推定 (Pose Estimation):
RLE (Residual Log-Likelihood Estimation)技術を採用することで、関節点(キーポイント)の推定精度を大幅に高めつつ、デコード処理の計算負荷を軽減しています。 - 回転物体検出 (OBB): 空撮画像や工業製品の検査で重要な回転矩形の検出において、角度損失(Angle Loss)の計算を最適化し、回転した物体の境界付近での検出精度を改善しました。
- 画像分類: 効率的なグローバルプーリングを活用し、高速な画像分類を実現しています。
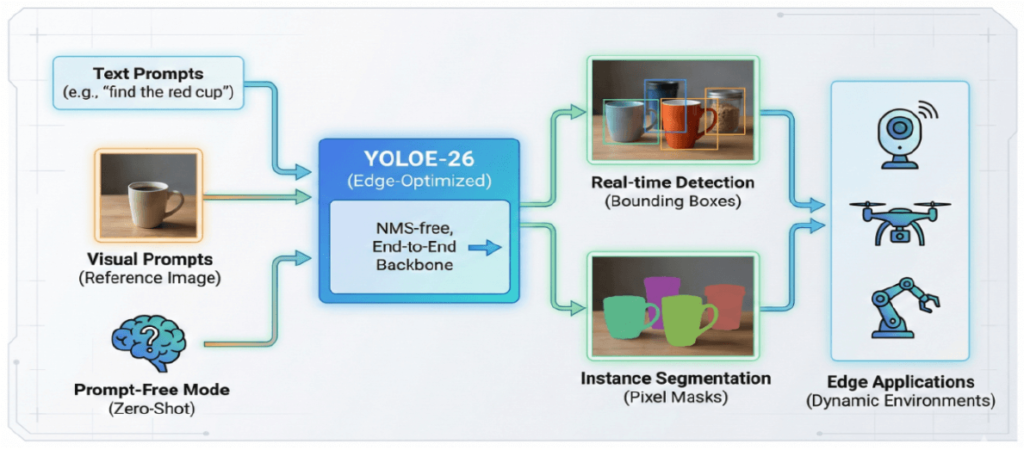
YOLOE-26とOpen-Vocabulary:未知の物体を捉える
YOLO26の最大の拡張機能の一つが、「YOLOE-26」によるOpen-Vocabulary対応です。 従来のモデルは、学習時に定義されたクラス(例:COCOデータセットの80クラス)しか検出できませんでした。しかし、YOLOE-26では、再学習(Fine-tuning)を行うことなく、プロンプト(手がかり)を与えることで学習データに含まれていない「未知の物体」を検出・分割することが可能です(ゼロショット/フューショット推論)。
- テキストプロンプト: 「赤いカップを見つけて (find the red cup)」のように、自然言語で探索対象を指示できます。
- ビジュアルプロンプト: 探したい物体の参考画像(例:特定の商品パッケージ)を提示することで、その特徴に基づいた検出が可能です。
- プロンプトフリーモード: ユーザー入力なしで、RAM++などの大規模語彙セット(4,000クラス以上)に基づいた広範な認識を自動的に行うこともできます。
これにより、工場のラインで新しい部品が追加された場合や、特定の遺失物を探すセキュリティ用途など、再学習のコストをかけずに、日々変化する現場の要件へ即座に対応できる柔軟性を実現しました。
5. Pythonによる利用方法
YOLO26は、これまでのYOLOシリーズ同様、ultralytics パッケージを通じて非常にシンプルに利用できます。ここでは、環境構築から推論、そして実務で役立つ「Dual-Head」の切り替え方法について解説します。
ライブラリのインストール
YOLO26を利用するには、Python 3.8以上およびPyTorch 1.8以上の環境が必要です。以下のコマンドでパッケージをインストール(または更新)してください。
pip install ultralytics
基本的な推論コード
事前学習済みモデル(例:最も軽量な yolo26n.pt)をロードし、画像に対して推論を行う最小限のコードは以下の通りです。YOLO26はデフォルトでNMSフリーのエンドツーエンドモードで動作するため、複雑な後処理コードを書く必要はありません。
from ultralytics import YOLO
# 事前学習済みのYOLO26 Nanoモデルをロード
model = YOLO("yolo26n.pt")
# 画像に対して推論を実行(戻り値はResultオブジェクトのリスト)
results = model("path/to/image.jpg")
# 結果の表示(または保存)
results.show() # 画像をウィンドウで表示
Dual-Headアーキテクチャの実践的活用
実務的な観点でYOLO26がユニークなのは、「One-to-Oneヘッド(高速・NMS不要)」と「One-to-Manyヘッド(高精度・NMS必要)」の両方を備えている点です。
- One-to-One Head (デフォルト): 推論時にNMSを必要とせず、最大300個の検出結果を出力します。エッジデバイスへのデプロイや最速の応答速度が必要な場合に最適です。
- One-to-Many Head: 従来のYOLOと同様にNMS後処理を必要とします。わずかなレイテンシ増加と引き換えに、より高い精度(Recall)が得られる場合があります。
エンジニアは end2end 引数を使用することで、用途に応じてこの挙動を制御できます。例えば、ONNXへのエクスポート時や推論時に従来の挙動(NMSあり)を選択したい場合は、以下のように False を指定します。
# One-to-Manyヘッド(NMSありの従来型挙動)を使用する場合
results = model.predict("image.jpg", end2end=False)
# モデルをONNX形式にエクスポート
path = model.export(format="onnx")
多様なタスクへの対応
YOLO26のフレームワークは物体検出だけでなく、セグメンテーションや姿勢推定などにも統一されたAPIで対応しています。タスクの切り替えは、読み込むモデルファイルのサフィックスを変更するだけです。
- 物体検出:
yolo26n.pt - セグメンテーション:
yolo26n-seg.pt - 姿勢推定 (Pose):
yolo26n-pose.pt - 回転物体検出 (OBB):
yolo26n-obb.pt
おわりに
YOLO26は、単にベンチマーク上の精度(mAP)を追求しただけのモデルではありません。その真価は、NMSフリー化とDFL排除によって「理論値と実効速度の乖離(Export Gap)」を解消し、学習時の性能を実環境でもそのまま発揮できる点にあります。
特に、GPUリソースが限られるエッジデバイスや、厳密な応答速度が求められるリアルタイムシステムにおいて、YOLO26が提供する「決定的レイテンシ(Deterministic Latency)」は強力な武器となるはずです。CPU推論においても最大43%の高速化を実現したこの新モデルは、エッジAI開発の新たなスタンダードになり得るでしょう。
ぜひ、ultralytics パッケージを通じて、その圧倒的な推論速度と実装の容易さを体感してみてください。次世代のエッジAI開発は、ここから始まります。
More Information
- arXiv:2601.12882, Sudip Chakrabarty, 「YOLO26: An Analysis of NMS-Free End to End Framework for Real-Time Object Detection」, https://arxiv.org/abs/2601.12882
関連記事

ベイジアンネットワーク入門:pgmpyによる因果探索と因果推論の実践
近年の機械学習(ML)モデルは、ビッグデータ解析において非常に高い予測精度を達成しています。しかし、その意思決定に至るプロセスが不透明な「ブラックボックス」となってしまう課題が指摘されています。データから相関関係を発見す […]

iLTM: 表形式データ向けの大規模基盤モデル
表形式データのモデリングにおいて、長らく実務のデファクトスタンダードとして君臨してきたのは勾配ブースティング決定木(GBDT)でした。画像や自然言語の分野で深層学習が席巻する中、表形式データだけは「GBDTが最適解」とい […]
PyTorch Metric Learningではじめる深層距離学習
近年のAI技術の発展において、画像認識、自然言語処理、推薦システムなど、様々なタスクでデータ間の「類似性」を理解し、活用することが重要となっています。このような背景から、入力データを効果的な特徴空間にマッピングし、類似す […]