組込みシステムと量子化ニューラルネットワーク
深層ニューラルネットワーク(DNN)は、画像分類、音声認識、物体検出といった分野で優れた性能を発揮しますが、その実現には膨大な計算資源とメモリを要求します。一方で、モノのインターネット(IoT)の急速な普及に伴い、マイクロコントローラー(MCU)のようなリソースが限られた組込みデバイス上での機械学習(ML)モデルの展開への関心が高まっています。これらのMCUは、数百キロバイト程度のオンチップメモリ、低クロック速度、ミリワットオーダーの電力予算といった厳しい制約の下で動作します。
この課題を解決するため、Tiny Machine Learning(TinyML)というパラダイムが登場しました。TinyMLは、MLアルゴリズム、ハードウェアアクセラレーション、ソフトウェア最適化を統合し、組込みシステム上でDNNを効率的に実行することを目指します。中でも、量子化(Quantization)は、モデルパラメータを低ビット幅の表現に変換することで、メモリ使用量と計算コストを大幅に削減する極めて重要な技術です。今回は、量子化の基礎から応用技術、対応するハードウェアとソフトウェアフレームワーク、そして実際のアプリケーション事例について解説します。
量子化の基本
深層ニューラルネットワーク(DNN)は、画像分類、音声認識、物体検出といった分野で最先端の性能を達成していますが、その卓越した性能は数百万から数十億に及ぶ膨大なパラメータと、数十億の積和演算(MAC)操作を要求します。この計算負荷とメモリ要件は、リソースが限られたマイクロコントローラー(MCU)にとって大きな課題となります。
MCUは通常、オンチップメモリが数百キロバイト(多くの場合64KBから256KBの範囲)と限定されており、クロック速度も40MHzから400MHz程度と低く、電力予算もミリワットオーダーと厳しい制約の下で動作します。さらに、GPU(Graphics Processing Unit)やASIC(Application-Specific Integrated Circuit)アクセラレータとは異なり、多くのMCUは専用の浮動小数点ユニット(FPU)を持たないため、浮動小数点演算はソフトウェアによってエミュレートされることが多く、これが大幅なオーバーヘッドを引き起こします。
これらのリソース制約に対応し、DNNを組込みシステムで効率的に実行可能にするために、量子化が不可欠な技術として注目されています。
数値表現の効率化
ディープニューラルネットワークでは、重みや活性化といった数値パラメータがメモリに格納され、算術演算に使用されます。これらの数値の表現形式は、モデルの精度、ストレージ要件、計算効率に直接影響を与えます。
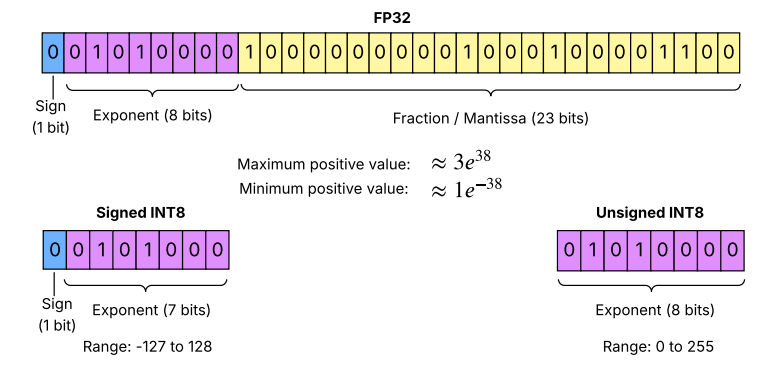
- 浮動小数点(FP32: Floating-Point 32-bit)
- 最も一般的な形式であり、高い精度と広いダイナミックレンジ(約\(10^{-38}\)から\(10^{38}\))を提供します。
- しかし、各値が32ビット(4バイト)を占めるため、メモリ使用量が多く、複雑な算術ハードウェアを必要とします。
- 高電力消費とシリコン面積の大きさから、低電力組込みシステムには不向きです。
- 固定小数点(INT8: Fixed-Point 8-bit)
- 実数をスケールされた整数として表現する形式であり、一般的に1バイト/値を使用します。
- シンプルな整数演算器を用いるため、FPUなしで演算が可能です。
- FP32と比較して、以下の点で大幅な効率化を実現します。
- メモリ削減: 4倍。
- MAC(積和演算)のエネルギー消費削減: 約20倍。
- 加算演算のエネルギー消費削減: 約30倍。
- 処理速度向上: 乗算で最大7.5倍、加算で最大3.3倍。
- これらの利点により、INT8はMCUでのエネルギー効率が高く、低遅延な推論に極めて効果的な選択肢となります。
量子化のプロセス
量子化は、DNNのモデルパラメータや中間的な活性化の数値精度を削減し、浮動小数点値を低ビット幅の表現(例:INT8)に置き換えるプロセスです。この際、モデル性能(例:精度)の損失を最小限に抑えることが目標となります。
量子化の基本的な変換関数は以下のように定義されます。
$$ \mathbf{x}_{\text{int}}=q(\mathbf{x};s,z)=\text{clamp}\left(\Big{\lfloor}\frac{\mathbf{x}}{s}+z\Big{\rceil};q_{\text{min}},q_{\text{max}}\right)$$
ここで、
- \(\mathbf{x}\) は元の実数値です。
- \(\mathbf{x}_{\text{int}}\) は量子化された整数値です。
- \(s\) はスケール(Quantization Resolution)で、量子化の分解能を定義します。
- \(z\) はゼロポイント(Quantization Bias)で、量子化された範囲をシフトさせるオプションの整数パラメータです。
- \(\lfloor \cdot \rceil\) は丸め操作(Rounding Operation)で、スケールされた入力を最も近い整数にマップし、量子化誤差を導入します。
- \(\text{clamp}()\) は結果を目標の整数範囲 \([q_{\text{min}}, q_{\text{max}}]\) 内に制限し、オーバーフローやアンダーフローを防ぎます。
量子化された整数値から近似的な実数値に戻す逆量子化(Dequantization)ステップは、以下の式で適用されます。
$$ \mathbf{x} \approx s \cdot (\mathbf{x}_{\text{int}} – z) $$
キャリブレーション
量子化では、変換の際の「クリッピングレンジ」\([q_{\text{min}}, q_{\text{max}}]\)を適切に決定することが重要です。このレンジの選択を誤ると、クリッピング誤差や大きな量子化誤差を引き起こす可能性があります。この適切なクリッピング境界を決定するプロセスをキャリブレーション(Calibration)と呼びます。
代表的なキャリブレーション手法は以下の通りです。
- Min-Maxキャリブレーション:
- 入力テンソル\(\mathbf{x}\)の全範囲をカバーするために、最小値と最大値をそのままクリッピングレンジとします。
q_min = min(x),q_max = max(x)。- シンプルですが、外れ値(Outliers)に非常に敏感であり、ダイナミックレンジを不均衡に拡大し、量子化の忠実度を低下させる可能性があります。
- MSE(Mean Squared Error):
- 外れ値の影響を軽減し、全体の量子化誤差を削減するため、元の値と量子化・逆量子化された値の間の再構成誤差(Reconstruction Error)を最小化するようにクリッピングレンジを選択します。
- パーセンタイルベースキャリブレーション:
- データセットの経験的分布に基づき、特定のパーセンタイル(例:1パーセンタイルを
q_min、99パーセンタイルをq_max)をクリッピングレンジの境界として選択します。 - これにより、極端な外れ値を効果的に除外し、層全体の量子化結果の堅牢性を向上させることができます。
- データセットの経験的分布に基づき、特定のパーセンタイル(例:1パーセンタイルを
量子化手法の設計選択肢
量子化の設計には、いくつかの重要な選択肢があり、それぞれがモデルの精度、計算コスト、ハードウェア互換性に影響を与えます。
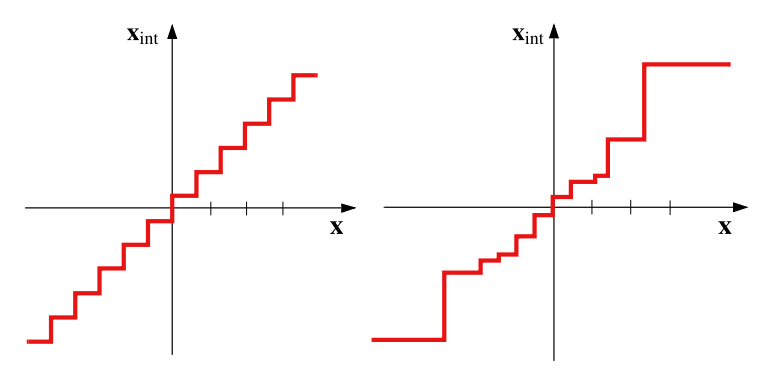
- 均等量子化(Uniform Quantization)と不均等量子化(Non-Uniform Quantization)
- 均等量子化:
- 量子化レベルが均等に配置されており、固定ステップサイズと丸め関数を用いて各浮動小数点値が最も近い整数レベルにマップされます。
- 固定小数点演算を用いた効率的な実装が可能であり、リソース制約のあるハードウェア(モバイル、組込みデバイスなど)での高速・低電力デプロイに広く採用されています。
- 不均等量子化:
- 量子化レベルが均等に配置されません。
- データ分布に合わせてステップサイズを調整し、密度の高い領域(例:ゼロ付近)に多くの分解能を割り当て、密度の低い領域には少ない分解能を割り当てます。
- 低ビット幅における精度向上に貢献しますが、高速な固定小数点線形演算との互換性が低く、ルックアップテーブルや非線形変換が必要となるため、ハードウェアへの実装が複雑になる場合があります。
- 均等量子化:
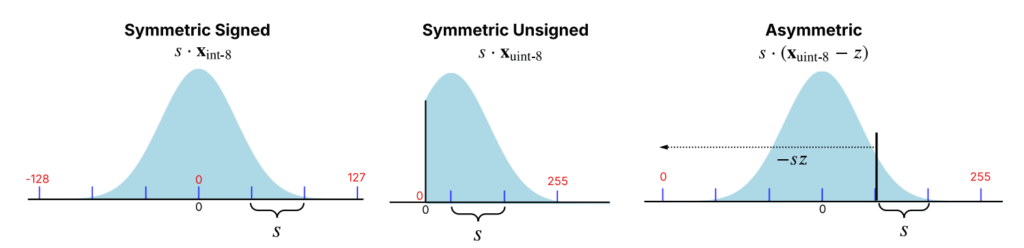
- 対称量子化(Symmetric Quantization)と非対称量子化(Asymmetric Quantization)
- 対称量子化:
- データがゼロを中心とした分布(例:ガウス分布)に従うと仮定します。
- 最小値と最大値が同等で符号が逆になり、ゼロポイント(Zero-point)は固定(通常は0)されます。これにより、ハードウェア実装と計算が簡素化されます。
- 対称署名付き量子化(Symmetric Signed Quantization)は、負の範囲と正の範囲にまたがる値に適しており、重みテンソルによく使われます。
- 対称署名なし量子化(Symmetric Unsigned Quantization)は、厳密に非負の値(例:ReLU演算後の活性化)に適しています。
- 非対称量子化:
- データがゼロを中心とするという仮定を取り除き、ゼロポイントを非ゼロに設定します。
- これにより、真のゼロが量子化ドメインで正確に表現可能となり、偏ったデータ分布(例:ReLU後の活性化)により柔軟に対応し、精度を向上させます。
- ゼロポイントの調整が可能になることで柔軟性が増しますが、ハードウェア実装の複雑さも増します。
- 対称量子化:
- 静的量子化(Static Quantization)と動的量子化(Dynamic Quantization)
- 静的量子化:
- クリッピングレンジ\([q_{\text{min}}, q_{\text{max}}]\)を、代表的なデータセットを用いたキャリブレーションフェーズで事前に計算し、固定します。
- 実行時のオーバーヘッドがないため、レイテンシが重要またはリソースが制約された環境でのデプロイに適しています。
- 入力の変化への適応性には欠けますが、そのシンプルさと効率性から広く採用されています。
- 動的量子化:
- スケールファクターとゼロポイントを、推論時にリアルタイムで(on-the-fly)入力活性化値の統計情報(min/maxやパーセンタイルなど)を用いて動的に計算します。
- 入力分布に正確に適応できるため、通常はより高い精度をもたらします。
- しかし、量子化パラメータを各入力ごとに再計算する必要があるため、計算オーバーヘッドが増加します。
- 静的量子化:
- 量子化粒度(Quantization Granularity)
- 量子化パラメータがニューラルネットワーク内で適用されるレベルを指します。粒度が粗いほど実装は単純になりますが、データ範囲の精度が低下し、モデルの精度が損なわれる可能性があります。
- グローバル(Global): ネットワーク全体で単一の量子化パラメータを共有します。ハードウェア実装が単純化され、メタデータストレージが削減されますが、層間の値分布の大きなばらつきにより、大幅な精度劣化につながることがよくあります。
- 層ごと(Per-tensorまたはPer-layer): 各テンソル(層)に固有の量子化パラメータを使用します。最も一般的な選択肢です。
- チャネルごと(Per-channel): 各出力チャネル(例:畳み込みフィルター)に独自の量子化パラメータを割り当てます。フィルター間のばらつきを捉え、量子化誤差を低減するため、より高い精度をもたらします。畳み込みカーネルの量子化においては、現在標準的な手法となっています。
- グループごと(Per-group): モデルをグループに分割し、各グループに固有の量子化パラメータを割り当てます。柔軟性と計算効率のバランスを取ります。
- トークンごと(Per-token): 主に言語モデルに適用され、個々のトークンに量子化パラメータを割り当てて、きめ細やかな精度を実現します。
量子化技術の深化 — より高い精度と効率を目指して
量子化は、ディープニューラルネットワーク(DNN)をリソース制約のあるマイクロコントローラ(MCU)にデプロイする上で不可欠な技術です。基本的な手法に加えて、モデル性能とハードウェア能力のバランスを最適化するため、さらに高度なアプローチが研究されています。ここでは、精度と効率を両立させるための先進的な量子化技術を紹介します。
推論後量子化(PTQ:Post-Training Quantization)
PTQは、事前学習済みの浮動小数点32ビット(FP32)モデルを、追加の訓練なしに量子化する手法です。
- メリットとデメリット:
- 実装が簡単で計算コストが低いため、特にデータ利用が制限される(プライバシー懸念やエッジデプロイメントなど)シナリオで有用です。
- しかし、量子化は各パラメータおよび入力に数値誤差を導入するため、これらの誤差が蓄積されると、特に低ビット幅では精度が低下する可能性があります。
- データ活用:
- PTQメソッドは、少量のキャリブレーションデータセットを用いて適切な量子化パラメータ(スケール、ゼロポイントなど)を推定する「データ駆動型」と、モデルの統計情報や合成データを利用する「データフリー型」に分類されます。
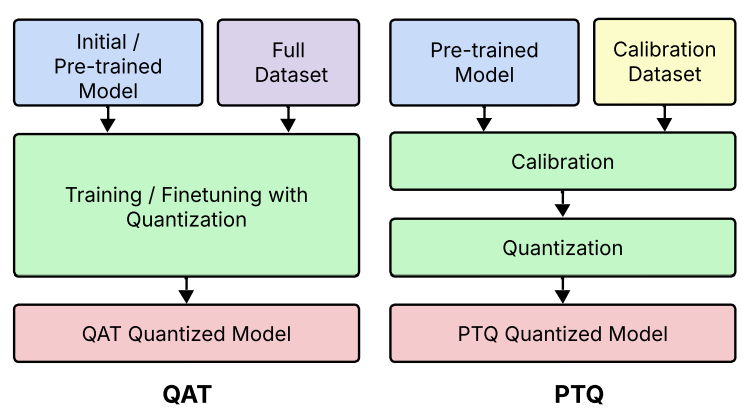
量子化認識訓練(QAT:Quantization-Aware Training)
QATはPTQの限界に対処し、訓練中に量子化効果をシミュレートすることで、モデルが量子化誤差に耐性のあるパラメータを学習するようにします。
- 精度の最大化:
- 訓練のフォワードパス中に「フェイク量子化」演算を挿入し、低精度(例:INT8)の推論時計算をシミュレートします。これにより、導入された誤差が最適化アルゴリズムによって最小化されるべき全体の損失の一部となります。
- 技術的側面:
- 量子化関数に含まれる非微分可能な丸め演算(\(\lfloor \cdot \rceil\))に対処するため、QATでは通常、Straight-Through Estimator (STE) を用いて勾配を近似します。STEは量子化関数をクリッピング範囲内で恒等関数として扱い、それ以外ではゼロの勾配を割り当てます。
- このアプローチにより、最適化プロセスは量子化による擾乱が損失値に与える影響が少ない「平坦な最小値」に収束するようにモデルを導きます。これにより、低精度でのデプロイ後の精度と汎化性能が向上します。
- 導入方法:
- QATは通常、事前学習済みのFP32モデルのファインチューニング段階として適用されます。この方法により、訓練オーバーヘッドを削減しつつ、高いポスト量子化精度を達成できることが示されています。
極低ビット量子化(Extreme Low-Bit Quantization)
極低ビット量子化は、効率性の限界をさらに押し広げるために、量子化された値を非常に小さな離散集合に制約する手法です。
- 究極の効率:
- 2値化(Binarization)は、重みと活性化を通常\({-1, +1}\)または\({0, 1}\)の2つの値のみで表現します。
- ターナリ化(Ternarization)は、\({-1, 0, +1}\)の3つの値を許容します。
- 利点:
- バイナリ化はFP32と比較して最大32倍のメモリ削減を実現します。
- コストの高い浮動小数点演算を、XNORやビットカウントといった軽量なビット単位演算に置き換えることができます。BNNは、最大19倍の高速化と8倍のメモリ削減を報告しています。
- 課題:
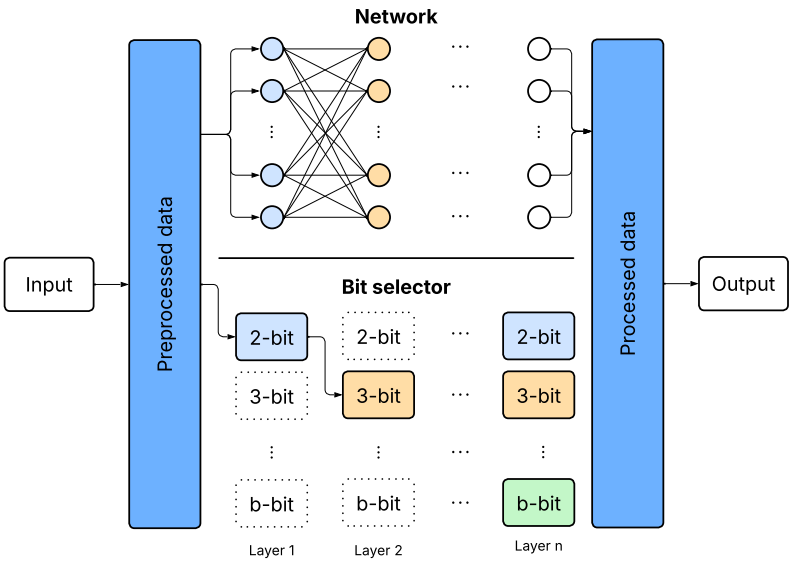
混合精度量子化(Mixed-Precision Quantization)
標準的な量子化ではモデル全体に均一なビット幅が適用されますが、混合精度量子化は、各層、チャネル、または活性化に異なるビット幅を割り当てることで、精度と効率の最適なバランスを見つけます。これは、各層が量子化誤差、推論時間、全体的なパフォーマンスに独自の影響を与えるという考えに基づいています。
- 手法: 混合精度戦略は、訓練中または推論後に行われます。
- Rough Allocation(大まかな割り当て): 重み行列のより広いパーティションに基づいてビット幅を割り当てる方法で、通常は推論後に行われます。
- HAWQ (Hessian-Aware Quantization) は、層の重み行列の2次ヘシアン情報(最大固有値)を計算し、感度が高い層にはより高い精度を割り当てます。
- 他の例として、Fisher情報行列を代替として用いるCherryQ、外れ値を優先するOWQ、HAWQの計算を全スペクトルに拡張したHAWQ-v2、第一次の量を用いて層の重要度を推定するHTQ などがあります。
- Adaptive Allocation(適応的割り当て): 訓練プロセス中にビット幅を動的に学習する学習ベースまたは微分可能な方法です。
- Rough Allocation(大まかな割り当て): 重み行列のより広いパーティションに基づいてビット幅を割り当てる方法で、通常は推論後に行われます。
ハードウェア認識量子化(HAQ:Hardware-Aware Quantization)
量子化の恩恵はデプロイ先のハードウェア特性に大きく依存するため、ハードウェア固有の制約と能力に合わせて量子化戦略を調整する必要があります。
- デプロイメントの最適化:
- HAQは、モデルの精度とサイズだけでなく、メモリ帯域、キャッシュ階層、オンチップメモリサイズ、低精度演算の命令サポートなど、ハードウェア固有の指標を考慮してビット幅構成を選択します。
- 探索空間の課題:
- 各層の重みと活性化に複数のビット幅候補が存在する場合、最適な構成を見つけるための探索空間は指数関数的に膨大となり、網羅的な探索は困難です。例えば、50層のResNetで各層が8つの候補ビット幅を持つ場合、探索空間は\(8^{50}\)になります。
- 解決策:
- 強化学習(HAQ) や整数線形計画法(HAWQ-v3) などの効率的な探索アルゴリズムが用いられます。HAWQは、Xilinx Zynq-7020 FPGAへのデプロイにおいて、均一なINT8量子化と比較してレイテンシを1.4〜1.95倍、エネルギーを1.9倍削減しました。
- On-Chip Hardware-Aware Quantization (OHQ) のように、量子化プロセス全体をエッジデバイス上で直接実行し、推定されるハードウェア性能と実際の性能との乖離をなくすアプローチも登場しています。OHQは、オフラインシミュレーションへの依存を排除し、精度と効率の両方で最先端のトレードオフを達成しています。
Redistribution(再分布)
量子化は情報の損失によって精度劣化を招くことが多く、特に非均一な分布やヘビーテール分布を持つ重みや活性化を扱う場合に顕著です。これらの影響を軽減するため、重みや活性化の統計的構造を調整し、低ビット表現に適した形にする再分布技術が重要です。
- データ分布の最適化:
- 分布の均一化 (Distribution Uniformization): ニューラルネットワークの重みや活性化は通常、ゼロ付近に集中するガウス分布やラプラス分布に従いますが、ユニフォーム量子化では最適ではありません。このミスマッチを軽減するため、重みや活性化の分布をより均一な形に再整形します。これにより、量子化レベルがより効果的に利用され、量子化誤差が減少します。
- 例: GDRQ (Group-based Distribution Reshaping Quantization)、KURE (Kurtosis Regularization)(分布の尖度を抑制)、SqWQ (Squashed Quantization)(重みを制限された区間に圧縮)、EQ-Net、KurTail などがあります。
- 外れ値の再分布 (Outlier Redistribution): 外れ値(極端な値)は量子化性能を著しく低下させるため、その影響を軽減することに焦点を当てます。
- SmoothQuant は、活性化と重みの両方にチャネル単位のスケーリング戦略を導入し、外れ値の影響を低減します。
- Hadamard変換は、外れ値を均等にチャネル全体に分散させることで、その全体的な影響を減少させます。
- DuQuant、AdderQuant、MagR などの手法も存在します。
- バイアス再分布 (Bias Redistribution): データ分布の中心傾向を調整し、量子化区間との整合性を高めることで表現効率を向上させます。
- 例: QuantSR(学習可能な平均シフトパラメータを導入)、NoisyQuant(固定の均一ノイズバイアスを追加)、RAOQ(活性化値をゼロから遠ざける学習可能なシフトを導入)などがあります。
- 分布の均一化 (Distribution Uniformization): ニューラルネットワークの重みや活性化は通常、ゼロ付近に集中するガウス分布やラプラス分布に従いますが、ユニフォーム量子化では最適ではありません。このミスマッチを軽減するため、重みや活性化の分布をより均一な形に再整形します。これにより、量子化レベルがより効果的に利用され、量子化誤差が減少します。
マイクロコントローラへのデプロイ
リソースに制約のあるマイクロコントローラ(MCU)への量子化ニューラルネットワーク(QNN)のデプロイは、モデル性能、計算量、メモリ制約のバランスを取る上で重要な課題を提示します。Tiny Machine Learning (TinyML) のパラダイムは、機械学習アルゴリズム、ハードウェアアクセラレーション、ソフトウェア最適化の進歩を統合することで、組み込みシステムでディープニューラルネットワーク(DNN)を効率的に実行することを可能にします。

ハードウェアの選択肢
MCUのランドスケープは、主にARMベース、RISC-Vベース、そしてNPU(ニューラル処理ユニット)を統合したハイブリッドシステムの3つのカテゴリに分類されます。
- ARMベースMCU
- 業界標準と特徴: 世界中のMCU市場で最も普及しているのはArm Cortex-Mシリーズ、特にCortex-M4です。これらのコアは、低コストとエネルギー効率に最適化されています。Cortex-M4は32ビットのRISCプロセッサであり、ARMv7E-M命令セットアーキテクチャ(ISA)に基づいています。内蔵DSP(デジタル信号処理)モジュールは、MAC(積和演算)やSIMD(Single Instruction, Multiple Data)演算(16/32ビットMAC、8/16ビットSIMD)を1クロックサイクルで高速化します。
- 浮動小数点演算の課題: 多くのモデルにはFPUが非搭載であり、その場合、浮動小数点演算はソフトウェアエミュレーションで行われ、大きなオーバーヘッドが発生します。FPUを搭載したモデル(例:Cortex-M4F)は、これらのタスクを大幅に高速化できます。
- ソフトウェアサポート: Cortexプロセッサは、推論のためにCMSIS-NNライブラリを一般的に使用します。これはARMv7E-MのSIMD命令を活用し、畳み込み、活性化、全結合層、プーリング、ソフトマックスといったDNNのカーネルを最適化します。TensorFlow Lite for Microcontrollers (TFLM) も内部でCMSIS-NNを利用しているため、同様の制約を受けます。
- RISC-VベースMCU
- オープンソースの利点: ARMベースMCUのプロプライエタリな性質と固定ISAの限界に対処するため、研究コミュニティはRISC-Vに注目しています。このオープンソースで拡張可能なISAは、特定のニーズ(電力、面積、性能)に合わせた高度にカスタマイズされたハードウェアソリューションの設計を可能にします。
- エコシステム: University of BolognaとETH ZurichのPULPプラットフォームが開発基盤となっており、エネルギー効率の高いRISC-Vコア(RI5CYなど)を統合しています。ここからGreenwave TechnologiesのGAP8やGAP9のようなマルチコアRISC-V MCUが登場し、オンチップRAMとフラッシュメモリを備え、堅牢なエッジAIワークロードに対応します。
- 低ビット幅サポート: XpulpNNのようなRISC-V ISA拡張は、低ビット幅SIMD演算をネイティブでサポートし、アンパックなしで直接パックされたSIMD計算を可能にします。これにより、SIMDレーンの利用率が最大化され、著しい効率向上を実現しました。
- NPU搭載ハイブリッドMCU
- 専用アクセラレータ: 近年、従来のCPU(ARM Cortex-Mプロセッサなど)と専用のニューラル処理ユニット(NPU)を組み合わせたハイブリッドMCUプラットフォームが登場しています。これらはMCUベースのシステムが抱える多くの課題に対処し、超低電力エッジアプリケーション向けに効率的なオンデバイス深層学習を可能にします。
- 性能: これらのプラットフォームは、行列乗算や畳み込みといった計算負荷の高い操作を加速し、超低電力プロファイルを維持しながら大幅な速度向上を実現します。代表的な例としては、Maxim IntegratedのMAX78000/02(30 GOPSのCNNアクセラレータ搭載)、STMicroelectronicsのSTM32N6(ST Neural-ARTアクセラレータ搭載、0.6 TOPS)、HimaxのHX6538 WE2(ArmのEthos-U55 NPU搭載、512 GOPS) などがあります。これらはCPUだけでは困難なリアルタイムAI推論を実現します。
- 極低ビット幅サポート: これらのNPUは主にCNNアクセラレータとして設計されており、1、2、4、8ビットといった超低ビット幅の重みをネイティブでサポートし、密なメモリパッキングと真のビット単位のアクセラレーションを可能にします。
主要ソフトウェアフレームワーク
MLモデルをMCUのようなリソース制約のあるデバイスにデプロイするためには、効率的なソフトウェアフレームワークが不可欠です。
- TensorFlow Lite for Microcontrollers (TFLM):
- MCU向け最適化: TensorFlow Liteの専門バージョンであり、特にCortex-MおよびESP32ベースのMCU上でTinyMLモデルを実行するために設計されています。
- リソース効率: 主要コンポーネントとして、必要な操作のみをモデルバイナリファイルにリンクするオペレーターリゾルバーと、初期化およびランタイム変数を格納するための静的に割り当てられた連続メモリスタック「アリーナ」を使用します。これにより、メモリ断片化の問題を回避するために動的な拡張を防ぎ、リソース効率を最適化します。
- 制約: しかし、TFLMはオンデバイス訓練のサポートを欠いており、静的メモリ割り当てに制約があります。
- PyTorch Edge (ExecuTorch):
- 次世代ランタイム: PyTorch Mobileの後継となる、モバイル、組み込み、MCUプラットフォーム向けの軽量C++ランタイムです。
- 高度な機能: 効率的な
torch.exportパイプライン、動的メモリプランニング、およびXNNPACK、CoreML、Vulkan、ベンダーAPIを介したハードウェア委譲をサポートします。PyTorchエコシステムとの緊密な統合を目指して設計されており、現時点では推論のみをサポートしています。
- その他のツール:
- STM32Cube.AI: STMicroelectronicsが提供するソフトウェアスイートで、STM32 Cortex-MベースMCUにDNNをデプロイするために特化しています。KerasやTensorFlow Liteモデルとのシームレスな互換性を提供し、効率的なランタイムメモリ最適化を可能にします。
- Edge Impulse: IoTデバイスからのデータ収集、特徴抽出、クラウドプラットフォームでのモデル訓練、TinyMLデバイスへのデプロイメントと最適化までを網羅する包括的なエンドツーエンドソリューションです。モデルをC/C++ソースコードに直接コンパイルするEONコンパイラを使用し、リソース利用を最適化します。
- ai8x-training/synthesis: Maxim IntegratedのMAX78000向けに開発されたツールチェーンです。PyTorchベースの
ai8x-training環境と連携し、量子化を考慮した訓練済みモデルを高度に最適化された組み込みCコードに変換します。 - TinyMaix: Sipeedによってリリースされた、マイクロコントローラ向けの超軽量ニューラルネットワーク推論ライブラリです。Arduino UNOのようなリソース制約の厳しいMCUでも基本的なCNNモデルを実行できるほどコンパクトで、静的メモリ割り当てと高効率コードを使用します。
- NNoM (Neural Network on Microcontroller): マイクロコントローラ上で複雑なディープラーニングモデルをデプロイするための高レベルな推論ライブラリです。C言語ベースのモデル表現で、ネットワークのグラフ構造、メモリ使用量、実行フローを内部で管理し、開発者の手間を最小限に抑えます。
QNNの実用アプリケーション事例
QNNは、その効率性と低リソース要件から、多岐にわたるエッジアプリケーションで活用されています。
- ヘルスケア: ウェアラブルデバイスにおける心拍数推定 、心不整脈診断 、発作検出 、および音声支援補聴器 など、リアルタイムで生命にかかわるデータの分析に貢献しています。
- 物体検出: スマートカメラやドローンにおけるリアルタイム物体検出 は、監視、ナビゲーション、セキュリティといった分野で重要な役割を果たします。
- 人間活動認識(HAR): ウェアラブルセンサーを用いた活動認識 は、フィットネスモニタリング、高齢者の転倒検知、スマートホームシステムなどで利用されます。
- 環境モニタリング: マイクロプラスチック検出 、火災検出 、ガスセンサーのドリフト補償 、野生生物分類 など、環境保護や災害予防に寄与します。
- 農業: 植物病害の認識 や、害虫監視ドローン による精密農業は、生産性向上と持続可能性の実現に貢献します。
- 音声処理: キーワードスポッティング やスピーチ強調 は、音声アシスタント、IoTデバイスの音声制御、アクセシビリティ技術などで広く利用されています。
おわりに
今回は、マイクロコントローラー(MCU)といったリソースが極めて限られた組込みシステム上で深層学習モデルを効率的にデプロイするための中心技術である量子化ニューラルネットワーク(QNN)について、その基礎から応用までを包括的に解説しました。
現在、実用的なエッジデプロイメントにおいては、INT8量子化(PTQおよびQAT)が主流であり、特にパーチャネル量子化、バイアス補正、交差層均等化、そして量子化認識ファインチューニングが最も効果的な手法として確立されています。また、近年急速に普及しているNPU(Neural Processing Unit)を搭載したハイブリッドMCU(例: Ethos-U/STM32N6、MAX78000/78002、GAP8/9)は、専用ツールチェーンと組み合わせることで、低ビット幅推論に対応し、レイテンシー、エネルギー消費、精度のトレードオフをより予測可能にしています。
ソフトウェアフレームワークは進化を続けていますが、TFLMの静的メモリ割り当て、オペレーターカバレッジの不均一性、サブ8ビットサポートの不足など、まだ課題も残っています。以前「ディープラーニングモデルの量子化: PyTorchによる実践解説」でPyTorchによる量子化方法を解説しましたが、今後はPyTorchベースのソリューションの台頭が予測され、動的なメモリ仮想化やエクスポーターとコンパイラの共同設計が、精度、遅延、エネルギー、メモリを統合的に最適化する道を拓くと考えられます。
今後の主要な研究方向としては、主流フレームワークでのサブ8ビット量子化と混合精度のサポート拡大、オンデバイス学習(継続学習やフェデレーテッドラーニングを含む)の実現、Transformerなどの非畳み込みニューラルネットワークアーキテクチャへの対応強化、そして基盤となるハードウェアアーキテクチャと量子化パラメータの共同最適化(ハードウェア認識共同設計)の推進が挙げられます。これらの進歩が、極限のエッジにおける信頼性が高く、低遅延でエネルギー効率の高いAIの実現を加速するでしょう。
More Information
- arXiv:2508.15008, Hamza A. Abushahla et al., 「Quantized Neural Networks for Microcontrollers: A Comprehensive Review of Methods, Platforms, and Applications」, https://arxiv.org/abs/2508.15008
関連記事

DINOv3: 自己教師あり学習による汎用ビジョン基盤モデル
高精度なAIモデルの構築には、大量かつ高品質な手動アノテーションが不可欠ですが、これは時間、コスト、労力の大きなボトルネックとなっています。特に医療画像や衛星画像のような特殊なドメインでは、ラベリングが極めて困難です。 […]

OpenVINOによる深層学習モデルのパフォーマンス改善
機械学習モデルの社会実装が加速する現代において、その推論速度は、アプリケーションの応答性、ひいてはユーザー体験を左右する重要な要素となっています。リアルタイム性が求められるエッジAIの現場から、大量データを処理するクラウ […]

距離学習入門 ~様々なタスクに応用できる機械学習手法~
距離学習(Metric Learning)は、データ間の類似度を学習する 機械学習の一手法です。従来の教師あり学習が、与えられたデータから特定のラベルや値を予測することを目的とするのに対し、距離学習は、データ間の関係性そ […]