DEAP入門:Pythonによる進化的計算の事始め

近年、深層学習(Deep Learning, DL)や大規模言語モデル(Large Language Models, LLM)といったAIシステムが目覚ましい進化を遂げています。しかし、それに伴い、これらの複雑なモデルの最適な構造設計やハイパーパラメータの決定は、従来の機械学習モデルと比較して、遥かに大きな複雑性の課題を抱えています。
このような複雑な最適化の要求に応えるため、進化的計算(Evolutionary Computation, EC)が強力かつ汎用性の高いツールとして注目されています。ECは、ドメインにとらわれず、モデルの構造とパラメータを同時に最適化できる強力な手法です。
今回は、この進化的な最適化手法の基礎を解説し、Pythonで進化アルゴリズムを柔軟に実装するためのフレームワークであるDEAP(Distributed Evolutionary Algorithms in Python)に焦点を当てます。DEAPは、事前に定義された型に限定するのではなく、ユーザーが個体、初期化、演算子などを自由にカスタマイズできる設計思想を持っています。その柔軟なモジュール性により、進化アルゴリズムを容易にカスタマイズすることができます。
進化的計算とは?
進化的計算(Evolutionary Computation, EC)は、生物の自然選択や適応、あるいは動物の群れの行動原理から着想を得た、最適化アルゴリズムの包括的なファミリーを指します。このアプローチの最大の特徴は、ドメインに依存しない(Domain-agnostic) 汎用性の高い最適化ツールとして機能する点にあります。
ECは、特定のデータやモデルの構造について事前知識や仮定を一切必要としないメタヒューリスティックな探索手法です。そのため、従来の最適化手法では探索が困難な、巨大で複雑な探索空間を持つ問題や、目的関数がスムーズでない(非微分可能な)問題に対しても、強力な解決能力を発揮します。
ECの構成要素
進化的計算は、単一のアルゴリズムを指すのではなく、その名の通り「進化」という概念に基づく広範な技術の集合体です。
ECのファミリーに含まれる主要なカテゴリーには、以下のようなものが挙げられます。
- 進化的アルゴリズム(Evolutionary Algorithms, EA)
- 群知能(Swarm Intelligence)
- 自己組織化(Self-organization)
- 差分進化(Differential Evolution)
これらのうち、中心となる進化的アルゴリズム(EA)には、さらに以下のような代表的なパラダイムが含まれています。
- 遺伝的アルゴリズム(Genetic Algorithms, GA): 個体(解候補)を符号化し、交叉(Crossover)や突然変異(Mutation)といった遺伝的操作を適用することで、集団を世代ごとに進化させます。
- 遺伝的プログラミング(Genetic Programming, GP): モデルのパラメータではなく、プログラムや関数の構造そのものを進化させる手法です。
- 進化的戦略(Evolutionary Strategies, ES): 主に連続的な最適化問題に適用され、特に変異のスケール(ステップサイズ)を自己適応させることに焦点を当てています。
- 進化的プログラミング: 特定の進化的操作を用いて解を改善していく手法です。
また、ECの範疇で広く利用される群知能の代表例としては、粒子群最適化(Particle Swarm Optimization, PSO)があります。ECは、これらの多様なアルゴリズムを通じて、機械学習(Machine Learning, ML)パイプラインの様々な段階(前処理、モデリング、後処理など)の最適化に貢献してきました。

ECが持つ独自の強み
ECの採用が特に有効となるのは、その柔軟性と適応性にあります。
ECが持つ独自の強みと利点は以下のとおりです。
- 仮定からの解放: データやモデルの特性について前提条件を必要としないため、従来の最適化手法が適用できない問題にも適用可能です。
- 構造とパラメータの同時最適化: モデルの構造設計(例:層の数や接続)と、それに伴うパラメータ(例:重みやハイパーパラメータ)の両方を同時に構築・最適化することができます。
- 多目的最適化への適合性: 集団ベースの探索アプローチを採用しているため、性能、複雑さ、ロバスト性といった複数の相反する目的(多目的最適化)を同時に考慮し、バランスの取れた複数の解(パレート最適解)を発見するのに特に適しています。
- 動的な問題への適応性: 時間の経過とともに変化する環境や目標(動的最適化)への適応性を高める能力も持ち合わせています。
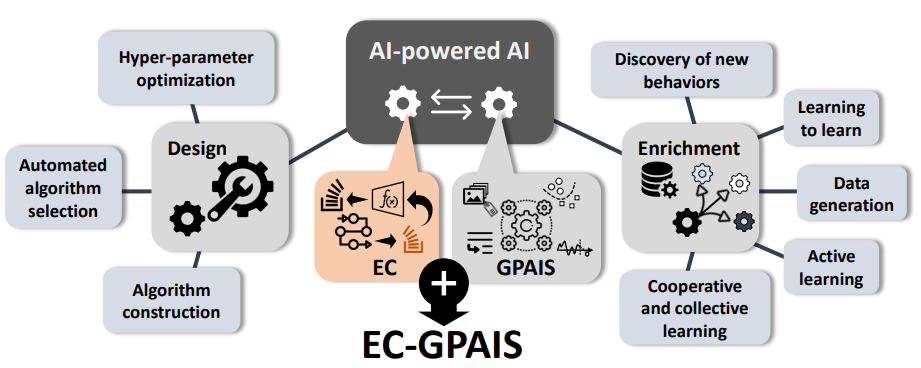
これらの特性から、ECは、最適な設計が極めて複雑になった深層学習(DL)や汎用AIシステム(GPAIS)の分野において、構造の自動化や自己適応を実現するための重要なメカニズムとして期待されています。
進化的計算の応用事例
進化的計算は、単なる数値パラメータの最適化に留まらず、AI/MLシステム設計の複数の段階で、その能力を発揮してきました。ECは、前処理、モデリング、後処理といった、機械学習パイプラインの多様なフェーズの最適化に広く用いられてきた経緯があります。
AutoMLの強化
AutoMLは、ECが最も顕著な貢献を果たしてきた分野の一つであり、特に複雑なAIモデルの設計において重要な役割を担っています。
- ハイパーパラメータ最適化(HPO)
遺伝的アルゴリズム(GA)や粒子群最適化(PSO)といったヒューリスティック手法を利用し、最適なハイパーパラメータセットを探索します。このプロセスでは、単にパフォーマンスを追求するだけでなく、複雑性やロバスト性といった複数の目的を同時に考慮に入れることが可能となっています。 - ニューラルアーキテクチャ探索(NAS)
深層学習モデルの最適なネットワーク構造(アーキテクチャ)を自動的に設計・選択する進化的なNAS手法は、大きな注目を集めています。ECの探索能力を活用することで、人間による設計が困難な大規模かつ高次元の探索空間を持つアーキテクチャの自動構築が可能になります。NASの多くの提案は、モデル選択とハイパーパラメータ最適化を統一的なタスクとして扱っています。

複雑な最適化と効率化への対応
ECの集団ベースの探索アプローチは、複数の競合する設計目標のバランスを取る、多目的最適化(Multi-objective Optimization)に特に適しています。
ECは、モデルの性能と計算コストや複雑性という相反する目的を同時に最適化する課題に対応します。例えば、NSGA-NetやMOAZといった研究では、性能と複雑性のトレードオフを考慮したパレート最適解を探索することで、複数の設計目標間でバランスの取れたモデルを提供します。
また、システム効率の向上にもECは貢献しています。トレーニングや推論のコスト削減のため、ECを利用して以下のような手法が実現されています。
- データ蒸留(Data Distillation): 学習データセットの削減による訓練コストの軽減。
- モデルの圧縮: モデルのプルーニング(枝刈り)や量子化による複雑性の低減。
適応性と汎用性の実現
汎用的なAIシステム(GPAIS)においては、未知のタスクや変化する環境への適応性と知識の再利用が重要な特性となります。
- 動的環境への適応: ECの動的最適化アルゴリズムは、データ分布の変化(データシフトやコンセプトドリフト)に対応するため、モデルの知識調整を行う上で非常に有用です。
- 知識の転送と再利用: 既存の知識を新しいタスクへ効率的に転送するため、ECは進化的転移学習(Evolutionary Transfer Learning, ETL)や進化的マルチタスク最適化(Evolutionary Multitask Optimization, EMO)と融合しています。EMOは、タスク間で知識を交換し、相乗効果を促進することで、複数のタスクを同時に学習する能力を高めます。ETLは、学習済みのパラメータ、表現、さらには演算子なども新しいタスクに転送することが可能です。ECのこれらの機能により、データが限定的であるZero-Shot学習やFew-Shot学習の状況下においても、既存の知識を最大限に活用し、高い汎用性を実現できるのです。
DEAPの基本概念と設計思想
DEAP(Distributed Evolutionary Algorithms in Python)は、進化アルゴリズム(EA)の実装を柔軟かつモジュール化することを主な目的として設計されたPythonライブラリです。他の多くのEAフレームワークとは異なり、DEAPはあらかじめ定義された型や固定されたアルゴリズムに利用者を制限しません。その代わりに、ユーザーが必要とするカスタムの構成要素を、非常に容易に構築できるように設計されています。この柔軟性こそが、DEAPの最大の特徴であり、多様な進化的計算のパラダイム(GA、GP、ES、PSO、DEなど)に対応できる基盤となっています。

柔軟な型生成:Creatorモジュール
DEAPにおいて、進化の基盤となる「型(Types)」を定義する中心的な役割を担うのがcreatorモジュールです。
個体(Individual)の「質」を評価するためのフィットネス(Fitness)クラスは、抽象基底クラスであるbase.Fitnessを継承して作成されます。このフィットネスオブジェクトを機能させるには、重み(weights)属性を定義する必要があります。
- 目的の定義:
weights属性に負の値を設定することで「最小化(Minimization)」問題が定義され、正の値を設定することで「最大化(Maximization)」問題が定義されます。 - 多目的最適化:
weightsをタプルとして複数の値を設定することで、多目的(Multi-objective)フィットネスを簡単に定義できます。例えば、weights=(-1.0, 1.0)と設定すると、第一目的は最小化、第二目的は最大化するフィットネスが作成されます。
このcreatorモジュールは、listやnumpy.ndarray、gp.PrimitiveTreeなど、Pythonの任意の型を基底クラスとし、定義したフィットネス属性を持つ個体(Individual)クラスを動的に生成することができます。通常、これは単一行のコードで行うことができます。
ツールのコンテナ:Toolboxクラス
Toolboxは、進化プロセスに必要なすべての「ツール」を格納するためのコンテナです。これには、個体や集団の初期化関数、評価関数(目的関数)、突然変異(Mutation)、交叉(Crossover)、選択(Selection)といった各種演算子が含まれます。
- 機能の登録:
toolbox.register(alias, function, *arguments)メソッドを使用することで、任意の関数をエイリアス(別名)を付けて登録し、引数の一部を固定することができます。 - 汎用性の確保: 評価を
toolbox.evaluate、交叉をtoolbox.mateといった一般的なエイリアスで登録することにより、アルゴリズムの本体(メインループ)から具体的な演算子の名称(例:tools.cxTwoPoint)を切り離すことができます。これにより、ユーザーはアルゴリズムの他の部分に影響を与えることなく、簡単に演算子を交換したり、カスタム演算子を組み込んだりすることが可能になり、汎用的なアルゴリズム開発が促進されます。
コアな演算子の設計思想
DEAPで提供される突然変異(mutate)や交叉(mate)といった遺伝的演算子には、明確な設計思想があります。
- インプレース(in-place)操作: これらの演算子は、個体をインプレース(その場で)で変更する役割のみを持ちます。例えば、交叉演算子は、提供された個体
ind1とind2を直接変更します。 - ユーザーの責任: 演算子の適用前に個体の複製(クローン)を作成したり、変更後に個体のフィットネスを無効化(削除)したりする責任は、アルゴリズムを記述するユーザー側に委ねられています。
これにより、アルゴリズムのループ内では、offspring = list(map(toolbox.clone, offspring))のように個体を複製し、変異や交叉が適用された後、del child1.fitness.valuesのように明示的にフィットネス値を削除する操作が必要となります。この設計は、DEAPを利用する上での重要なポイントです。
Pythonによる実践
ここまでのセクションで、進化的計算(EC)とDEAPの設計思想について理論的な側面を解説しました。このセクションでは、それらの知識を具体的なコードに落とし込み、実際にDEAPを使って機械学習の問題を解決するプロセスを体験します。
題材として、遺伝的アルゴリズム(GA) を用いてサポートベクタマシン(SVM)のハイパーパラメータ最適化(HPO)を行う実装を進めていきます。
インストール
はじめに、必要なライブラリをインストールします。DEAPに加えて、機械学習モデル(SVM)とデータセットのためにscikit-learn、数値計算のためにnumpyを使用します。
$ pip install deap scikit-learn numpy問題の定義:評価関数の実装
ECで最も重要なステップは、解候補(個体)の「良さ」を測る評価関数(目的関数)を定義することです。今回は、SVMの性能を評価するためのクラスIrisLossを実装します。このクラスが、GAが最大化を目指す「適応度」を計算する役割を担います。
このクラスでは、アヤメ(Iris)のデータセットを読み込み、指定されたハイパーパラメータ(Cとgamma)でSVMを訓練し、その精度(Accuracy)をスコアとして返します。
import random
import numpy as np
from deap import algorithms, base, creator, tools
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
class IrisLoss:
"""
A class that encapsulates the problem definition.
It handles dataset loading and the evaluation of an individual's fitness.
"""
def __init__(self) -> None:
# Prepare the dataset once during initialization.
self._x_train, self._x_test, self._y_train, self._y_test = self._load_dataset()
@property
def n_attributes(self) -> int:
# The number of parameters (genes) to optimize. In this case, C and gamma.
return 2
def score(self, weights: list[float]) -> float:
"""A simple scoring method for the final evaluation."""
svm = SVC(kernel="rbf", C=10.0 ** weights[0], gamma=10.0 ** weights[1])
svm.fit(self._x_train, self._y_train)
score = svm.score(self._x_test, self._y_test)
return float(score)
def __call__(self, weights: list[float]) -> tuple[float, float]:
"""
The main evaluation function used by DEAP's toolbox.
It takes an individual's genes (weights) and returns its fitness.
"""
# The GA searches in a logarithmic space (-4.0 to 4.0).
# We convert these values to a wide range for C and gamma (e.g., 0.0001 to 10000).
# This is a common and effective technique for hyperparameter tuning.
svm = SVC(kernel="rbf", C=10.0 ** weights[0], gamma=10.0 ** weights[1])
svm.fit(self._x_train, self._y_train)
train_score = svm.score(self._x_train, self._y_train)
test_score = svm.score(self._x_test, self._y_test)
# Return a tuple for multi-objective fitness (train and test scores).
return (float(train_score), float(test_score))
def _load_dataset(self) -> list[np.ndarray]:
"""Helper function to load and split the Iris dataset."""
x, y = load_iris(return_X_y=True)
return train_test_split(
x,
y,
test_size=0.3,
random_state=42,
)
GAの設定
次に、GAの進化プロセスを構成する各要素(遺伝子の生成方法、個体の構造、選択・交叉・突然変異の各演算子)をToolboxに登録します。これにより、アルゴリズムの本体から具体的な実装を切り離し、モジュール性を高めることができます。
def build_toolbox(mutation_ratio: float, objective: IrisLoss) -> base.Toolbox:
"""
Configures the DEAP toolbox with all the necessary components for the GA.
"""
toolbox = base.Toolbox()
# Defines a single gene. Each gene will be a random float between -4.0 and 4.0.
toolbox.register("attribute", random.uniform, -4.0, 4.0)
# Defines an individual (chromosome) as a collection of genes.
# It uses the 'creator.Individual' class and fills it with 'objective.n_attributes' genes.
toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.attribute, objective.n_attributes)
# Defines the population as a list of individuals.
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
# Defines the selection operator: Tournament selection.
toolbox.register("select", tools.selTournament, tournsize=20)
# Defines the crossover (mating) operator: Blended crossover, suitable for continuous values.
toolbox.register("mate", tools.cxBlend, alpha=0.1)
# Defines the mutation operator: Gaussian mutation.
toolbox.register(
"mutate",
tools.mutGaussian,
mu=[0.0] * objective.n_attributes,
sigma=[0.5] * objective.n_attributes,
indpb=mutation_ratio,
)
# Links the evaluation function from our IrisLoss class.
toolbox.register("evaluate", objective)
return toolbox
進化プロセスの実行
最後に、進化のプロセス全体を制御するメインの処理を記述します。creatorモジュールを使ってFitnessとIndividualの型を動的に定義し、初期集団を生成して進化のサイクルを開始します。
algorithms.eaSimpleは、DEAPが提供する基本的な進化的アルゴリズムの実装です。これに集団とToolboxを渡すだけで、あとは自動的に世代交代を進めてくれます。
def main(
n_indivisuals: int = 100,
n_generations: int = 20,
crossover_ratio: float = 0.7,
mutation_ratio: float = 0.2,
) -> None:
# --- Type Creation using 'creator' ---
# Create a 'Fitness' class. 'weights=(1.0, 1.0)' means we want to maximize
# both objectives returned by the evaluation function.
creator.create("FitnessMulti", base.Fitness, weights=(1.0, 1.0))
# Create an 'Individual' class based on a list, with the fitness attribute defined above.
creator.create("Individual", list, fitness=creator.FitnessMulti)
# --- Initialization ---
objective = IrisLoss()
toolbox = build_toolbox(mutation_ratio, objective)
# Create the initial population.
populations = toolbox.population(n=n_indivisuals)
# Evaluate the fitness of the first generation.
for individual in populations:
individual.fitness.values = toolbox.evaluate(individual)
# Set up statistics to be collected during the evolution.
stats = tools.Statistics(lambda ind: ind.fitness.values)
stats.register("avg", np.mean, axis=0)
stats.register("std", np.std, axis=0)
stats.register("min", np.min, axis=0)
stats.register("max", np.max, axis=0)
# --- Run the Evolutionary Algorithm ---
# This is the main evolutionary loop.
# cxpb: The probability of mating two individuals.
# mutpb: The probability of mutating an individual.
# ngen: The number of generations to run.
_ = algorithms.eaSimple(
populations, toolbox, cxpb=crossover_ratio, mutpb=mutation_ratio, ngen=n_generations, stats=stats, verbose=True
)
# --- Print the Best Result ---
# Select the best individual from the final population.
best_ind = tools.selBest(populations, 1)[0]
best_c = 10 ** best_ind[0]
best_gamma = 10 ** best_ind[1]
final_score = objective.score(best_ind)
print("\n--- Best Individual ---")
print(f"C = {best_c}")
print(f"gamma = {best_gamma}")
print(f"Final Test Score = {final_score}")
if __name__ == "__main__":
main()
このコードを実行すると、世代ごとの統計情報(平均、最大、最小スコアなど)が出力され、進化の過程を追跡できます。最終的に、最適化されたハイパーパラメータ C と gamma、そしてその時のテストスコアが表示されます。
DEAPのモジュール性により、例えば交叉戦略をtools.cxBlendからtools.cxTwoPointに変更したり、選択方法をtools.selTournamentからtools.selRouletteに切り替えることも、Toolboxの登録を一行変更するだけで簡単に行えます。この柔軟性が、DEAPが複雑な問題に対するカスタムアルゴリズムの探求を強力にサポートできる強みです。
おわりに
今回紹介したように、DEAP(Distributed Evolutionary Algorithms in Python)は、あらかじめ定義された型に縛られず、ユーザーのニーズに合わせて個体や演算子を自由に設計できる柔軟なモジュール性を提供します。この柔軟性こそが、遺伝的アルゴリズム(GA)、遺伝的プログラミング(GP)、進化戦略(ES)、粒子群最適化(PSO)といった多様な進化手法をPythonの環境で実現するための、強力なプラットフォームとなっています。
進化的計算(EC)は、機械学習モデルの設計と最適化において先駆的な役割を果たしてきた汎用的なアルゴリズム群であり、その適用は、汎用人工知能システム(GPAIS)のような、従来のモデルよりも遥かに大きな複雑性の課題を抱えるシステムに対して自然な選択肢となっています。ECは、モデルの構造の自動化、パラメータの最適化、さらには革新的な新しいアルゴリズムの創出にまで貢献する能力を持っています。
ECの持つ柔軟性と適応性の高さは、タスクの多様性や時間とともに変化する環境への対応といった、GPAISに求められる厳格な特性を満たす上で不可欠です。進化的計算の継続的な研究は、AIをより汎用的で、幅広いタスクを自律的に解決し、新しい課題に自己適応(Self-adapting)できるシステムへと進化させることを約束しています。DEAPのようなモジュール化されたプラットフォームを通じてECを活用することは、機械学習システムをより効率的で、適応性が高く、ロバストなものにするための重要な手段となります。
More Information
- arXiv:2407.08745, Javier Poyatos et al., 「Evolutionary Computation for the Design and Enrichment of General-Purpose Artificial Intelligence Systems: Survey and Prospects」, https://arxiv.org/abs/2407.08745
関連記事

OpenJij x PyQUBO ではじめるシミュレーテッド・アニーリング入門
組み合わせ最適化問題は、工学、金融、情報科学といった多様な分野において、実用上極めて重要な課題です。しかし、問題が複雑化し、探索すべき解の候補が爆発的に増加するにつれて、従来型の数学的な手法で厳密な最適解を求めることは困 […]

CMA-ES入門: 進化戦略によるブラックボックス最適化
現代のエンジニアリングにおいて、最適な解を見つけ出す「最適化」は常に重要な課題です。しかし、目的関数の内部構造が不明確である、あるいは解析的に勾配を計算できない場合、その問題はブラックボックス最適化(Black-Box […]

QUBOLite入門: 軽量QUBOツールキットによる最適解の高速探索
複雑な組合せ最適化問題に直面したとき、どのようにすれば高速かつ効率的に最適解を見つけられるでしょうか。近年、この難問へのアプローチとして、2次非制約二値最適化(QUBO: Quadratic Unconstrained […]